【Tableau】LOD計算とは?~世界一易しいLOD計算の説明(にしたい)~

Tableauを始めてから、LOD計算がなかなか理解できず本当に苦労しました。
師匠に教えていただいたり、いろいろな方のブログを拝読したりして理解できたことをここにまとめます。
打倒Tableau三大将🤛

こちら概要編になります。 FIXED・INCLUDE・EXCLUDEそれぞれの説明はこちらです。kaodora.hatenablog.com
LODとは
Tableauを使っていると「LOD」という言葉が当たり前のように使われているように思いますが、そもそも「LOD」ってなんだ!というところから始めます。
LOD・・・Level Of Detailの略、データの粒度、詳細レベル
そのデータは何を表しているか

例えば、このビューは何を表していますか。
このデータ全体の売上の合計を表しています。

こちらはどうでしょうか。
カテゴリごとの売上を表しています。言い換えればカテゴリという粒度で売上を集計していますね。
ここから、サブカテゴリ、製品idといういうようにディメンション(集計粒度)を足していけば、データの粒度は細かくなっていきます。
ここでいう「足していく」というのはビューに追加するということですが、下の画像の赤枠に入れるとことでデータの粒度が決定します。(フィルターとツールヒント以外)
最終的には元のデータ(↓)の行レベルになります。

LODとはデータの粒度のことで、ディメンションが多ければ多いほど粒度は細かくなることがわかりました。
では、本題です。LOD計算とはなんでしょうか。
LOD計算はなんで必要?

上のビューは「顧客ごとの」購入金額(売上)の平均を表しています。
では、地域ごとに「顧客ごとの」購入金額の平均を出すにはどうすればいいですか。
上のビューはどうですか。地域ごとに売上の平均を出してみました。
しかし、これでは「顧客ごとの」売上の平均ではないですよね。
売上の平均、というものを改めて整理してみると
売上(227,176,841)をデータの行数(10,000)で割っている数字です。このデータは1購入ごとに行が発生していると考えると、今表示されているビューは「1購入ごとの」売上平均ということになります。
地図のビューに戻ると、これは「1購入ごとの」売上の平均を地域ごとの表しているのです。
「1購入ごとの」という粒度で成り立っているこのデータでは、他の粒度でビューを作ろうとすると集計の自由度が下がってしまいます。
RFM分析に必要な「顧客ごとの最終購入日からの経過日数」や、「顧客ごとの購入金額」を出すときはどうすれば良いでしょうか。
そこで登場するのがLOD計算です。
LOD計算は集計の粒度をコントロールすることができるのです👏
LOD計算の仕組み
LOD計算とは、中間テーブルの作成を意味します。
こんなLOD計算を作ってみます。
{FIXED[顧客id]:AVG(売上)}
これは顧客ごとの売上の平均を出してね、という式です。
元のデータから顧客id売上を集計して平均を出しています。
これをビュー上の顧客id、製品idに載せてみると以下のようになります。この場合は同じ粒度なので中間テーブルは作成されません。
それでは、LOD計算にない他の粒度のディメンション(この場合は地域)に載せるとどうなるでしょうか。

顧客ごとの売上平均を出した後、中間テーブルで地域が北海道の顧客idを集めます。
ビュー上には地域ごとの、顧客idごとの売上平均が集計されます。
このようにLOD計算では中間テーブルが作られ、LOD計算にはない違う粒度のディメンションでも集計することができます。
LOD計算はパワフルだと言われる所以はここです。
逆をいえばビューにディメンションをおかずとも、ディメンションを追加することができるのです。(ここでは地域ごとの顧客idごとの売上平均が出ていますが、ビューに顧客idはおかれていませんよね。)

LOD計算の作り方

・ { ブレースをつける
・FIXED、INCLUDE、EXCLUDEを選択する
・ディメンションを入れる(場合によっては複数)
・ : コロンを入れる
・集計関数(SUM、AVG、COUNT、MAX、MIN等)、メジャーを入れる
・ } ブレースをつける
まとめ
LOD
何を表しているか。
データの粒度、ディメンションが多ければ多いほど粒度は細かくなる。
LOD計算
集計の粒度をコントロールすることができる
中間テーブルが作られ、LOD計算にはない違う粒度のディメンションでも集計することができる。
ビューにディメンションをおかずとも、ディメンションを追加することができる。
LOD計算は以下のように作る
・ { ブレースをつける
・FIXED、INCLUDE、EXCLUDEを選択する
・ディメンションを入れる(場合によっては複数)
・ : コロンを入れる
・集計関数(SUM、AVG、COUNT、MAX、MIN等)、メジャーを入れる
・ } ブレースをつける
LOD計算の使用例
【Tableau】DATASaber:HandsOn-Advanced l(Ord8)解説
はじめによんでください。kaodora.hatenablog.com
鬼のLOD計算三昧・・・👹
LOD計算の説明はこちらです。kaodora.hatenablog.com
個人的には全Ordの中でこれがダントツ難しいです!
Q1
Ord8(1)1/2 pic.twitter.com/TixdNN8KYz
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
この問題はパラメーターを使います。
上のようなパラメーターを作ります。表示名はそれぞれのシート名になります。
このパラメーターを計算フィールドに入れます。
それぞれのシートでパラメーターの編集を行い、現在の値をそれぞれのシート名に設定します。それから、計算フィールドの「グラフの切り替え」をフィルターの入れて表示名に対応した値にチェックを入れます。
Ord8(1)2/2 pic.twitter.com/7bkQXqNPHG
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
問題文にあるように、それぞれのチャートを広くスペースを使って表示するためにはレイアウトコンテナーを使います。
今回は垂直方向のレイアウトコンテナーを使い、それぞれのシートを入れていきます。
そして、パラメーターを表示させます。
それぞれのタイトルを非表示にして、ダッシュボード自体のテキストを表示し、「挿入」からパラメーターを入れて、シートに対応したシート名が表示されるように設定します。
Q2
Ord8(2) pic.twitter.com/0X5EdbQqmR
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
基準日を以下の計算で出します。
{MAX([オーダー日])}
このデータ全体のオーダー日最終日を出してね。名前は「基準日」にします。
顧客ごとの最終購入日を計算で出します。
{FIXED[顧客id]:MIN([オーダー日])}
顧客ごとの最終オーダー日を出してね。名前は「顧客ごとの最終購入日」にします。
上2つの式の差を出します。おなじみのDATEDIFF関数です。
DATEDIFF('day',[顧客ごとの最終購入日],[基準日])
'day'(日)の単位で顧客ごとの最終購入日と基準日の差を出してね。名前は「最終購入日〜基準日」にします。
「最終購入日〜基準日」のビンを60単位で作成し、顧客数(顧客idのカウント(個別))を行に入れて、テキストで最大値のみを表示させ回答を確認します。
Q3
Ord8(3) pic.twitter.com/8QngSc3KBZ
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
{FIXED[顧客 Id]:COUNTD([オーダー Id])}
顧客ごとのオーダー回数(オーダーidのカウント(個別))を出してね。名前は「顧客ごとの購入回数」にします。
この式を1単位のビンにして、顧客数(顧客idのカウント(個別))を出して、テキストで最大値のみを表示させ回答を確認します。
WINDOW_MAX(COUNTD([顧客 Id]))=COUNTD([顧客 Id])
表内の顧客数の最大値が顧客数と一致していたら真、それ以外は偽という式を色に入れます。
(オプション問題)
Ord8(3)オプション問題 pic.twitter.com/EAnpEM9zLT
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
{INCLUDE[オーダー Id]:SUM([売上])}
顧客idを考慮して、オーダーidごとの購入金額を出してね。
上の式を行に入れて、テキストで最大値のみを表示させ回答を確認します。
WINDOW_MAX(AVG([オーダーごとの購入金額]))=AVG([オーダーごとの購入金額])
表内の購入金額の最大値が購入金額と一致していたら真、それ以外は偽という式を色に入れます。
なんでFIXEDじゃなくてINCLUDEなの!

INLUDE初登場です👏
INDLUDE計算はビュー内のディメンションを考慮することができます。
では下の表で、INCLUDE計算とFIXED計算を比較してみましょう。

顧客id、オーダーid、顧客ごとの購入回数、合計(売上)、平均(売上)、INCLUDE計算、FIXED計算を並べました。赤枠で囲った2行目の数字をみていきます。
合計(売上)→オーダーidごとの売上の合計
平均(売上)→合計(売上)をオーダーid(カウント)で割った数字
上のようにサブカテゴリを入れてみると、オーダーidは複数ある場合があることがわかります。
INCLUDE計算→顧客idを考慮したオーダーidごとの購入金額
FIXED計算→オーダーidごとの購入金額
上のようにオーダーidは複数存在するため、FIXED計算だと、このオーダーidの全ての売上が足されてしまいます。
今回の問題では、顧客ごとの購入回数というビンに載せたいため、顧客を考慮する必要があります。そのためINCLUDE計算である必要があります。
ビュー内にあるものを考慮する関数なので、ここで、顧客idを取ればINCLUDEもFIXEDも値は同じになります。
逆に要素を足しても、それは全て考慮してくれます。ここでは、オーダーidとサブカテゴリを考慮したオーダーidごとの購入金額を出しています。
ここで・・・
クロス集計で合計(売上)とINCLUDE計算数字同じだから、ヒストグラムで平均にすればいいじゃん!で思った方いませんか!私なんですけども!!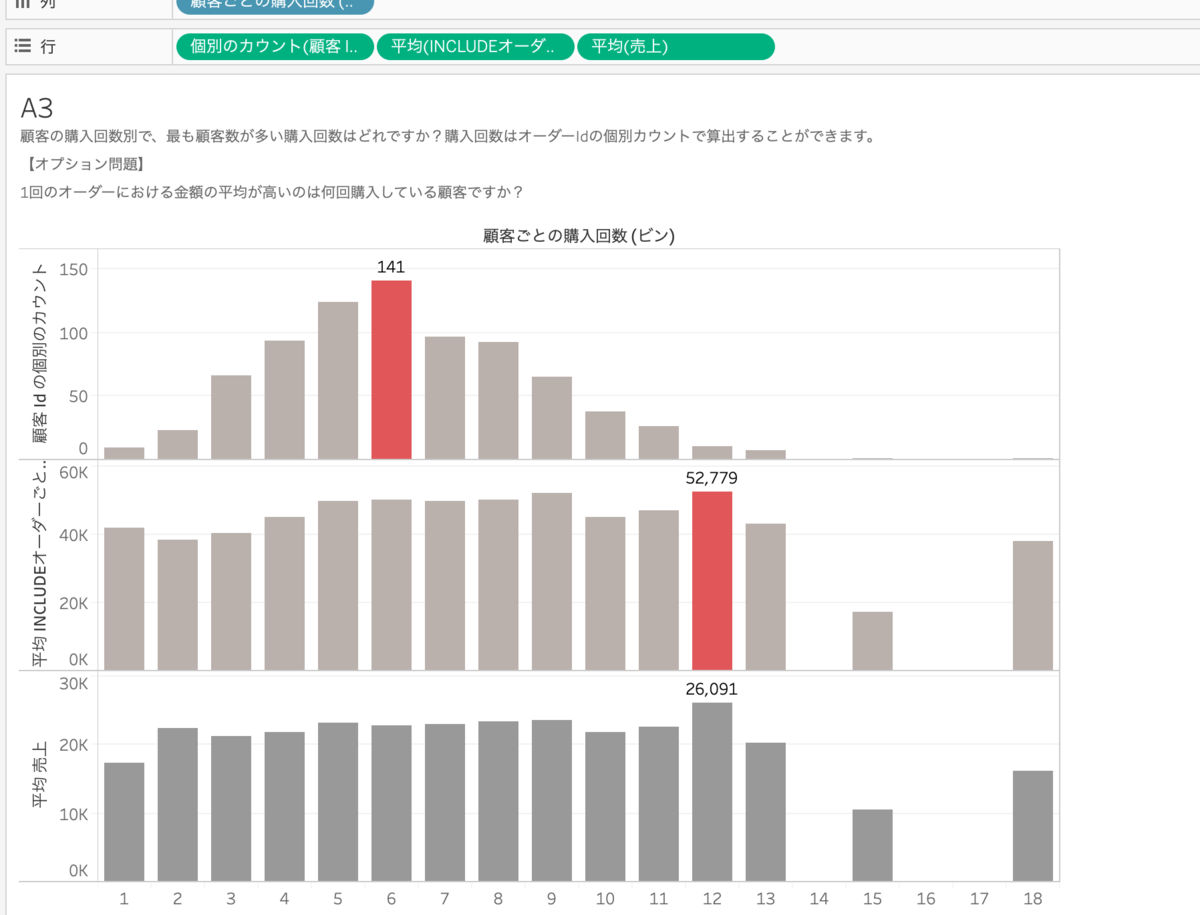
ヒストグラムに入れてみると、全然数字が違います。
先ほどにもありましたように、平均(売上)は合計(売上)をオーダーid(カウント)で割った数字です。
26,091という数字は購入回数が12回の顧客の売上を全て足してから、265で割っているのです。(オーダーidのカウント)
一方でINCLUDE計算も顧客を考慮したオーダーidごとの購入金額を、オーダー回数(オーダーidのカウント)で割っています。「オーダーidごとの」ということは、「個別のオーダーidごとの」ということですので、ここでのオーダー回数は実質オーダーidのカウント(個別)になるのです。
52,779という数字は購入回数が12回の、顧客を考慮したオーダーidごとの購入金額を全て足してから、132で割っているのです。(オーダーidのカウント)
全く粒度が異なる計算ということがわかりました。
問題文にあるように、ここではオーダーidごとの購入金額を知りたいので、INCLUDE計算を使う必要があります。
Q4
Ord8(4) pic.twitter.com/NUiD7DLIjx
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
{FIXED[顧客 Id]:SUM([売上])}
顧客idごとの購入金額を出してね。
上の式で、10万単位のビンを作成します。顧客数(顧客idのカウント(個別))を行に入れて、テキストで最大値のみを表示させ回答を確認します。
WINDOW_MAX(COUNTD([顧客 Id]))=COUNTD([顧客 Id])
表内の顧客数の最大値が顧客数と一致していたら真、それ以外は偽という式を色に入れます。
Q5
Ord8(5) pic.twitter.com/LpOurFg4HF
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
オーダー年ごとの売上を棒グラフで出します。
{FIXED[顧客 Id]:MIN([オーダー日])}
顧客idごとの最初のオーダー日を出してね。「顧客ごとの初回購入日」という名前にします。
顧客ごとの初回購入日を色に入れます。
売上を簡易表計算から(横)の合計に対する割合にします。
Q6
Ord8(6) pic.twitter.com/J2t3HgzROc
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
この問題は初回購入日と2回目の購入日の差を出したいのですが、2回目の購入日を出すために、2つ式を書きます。初回購入日はQ5で作成したものを使います。
IIF([オーダー日]>[顧客ごとの初回購入日],[オーダー日],NULL)
もし、オーダー日が顧客ごとの初回購入日より大きかったら、オーダー日を返してね。それ以外はNULLね。
{FIXED[顧客 Id]:MIN([2回目以降の購入日])}
顧客idごとの2回目の購入日(2回目以降の購入日の中で一番小さい数字)を出してね。
上の式を確認すると以下のようになっています。

DATEDIFF('quarter',[顧客ごとの初回購入日],[顧客ごとの2回目購入日])
'day'(日)の単位で顧客ごとの初回購入日と顧客ごとの2回目購入日]の差を出してね。名前は「初回~2回目購入日の差(四半期)」にします。
列に初回~2回目購入日の差(四半期)を、行に顧客ごとの初回購入日を四半期単位でおき、顧客数(顧客idのカウント(個別))でハイライト表を作成します。
テキストで最大値のみ表示させて、回答を確認します。
(オプション問題)
Ord8(6)オプション問題 pic.twitter.com/WIZXMNQV6W
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
Q4で作成した顧客ごとの購入金額をハイライト表に入れます。
そのまま入れると、色の判例が同じになってしまいますが、単位が全然違うので困ります。色に入っているメジャーバリューをクリックし、「別の凡例を使用」をクリックします。
初回~2回目購入日の差(四半期)が4四半期いないであれば購入金額が高いので、最低でも4四半期以内に2回目の購入を行ってもらいたいところです。
Q7
Ord8(7) pic.twitter.com/66HWcyJF6t
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
オーダー日(月)、オーダー日(曜日)を行、列にそれぞれ入れて、
オーダー日ごとの売上でハイライト表を作成します。
{FIXED[オーダー日]:SUM([売上])}
オーダー日ごとの売上を出してね。
テキストで最大値のみを表示させて、答えを確認します。
(オプション問題)
Ord 8(7)オプション問題 pic.twitter.com/JVQijHCUI4
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
オーダー日(月)、オーダー日(曜日)を行、列にそれぞれ入れて、
オーダー日ごとの売上でハイライト表を作成します。ここでのオーダー日ごとの売上はLOD計算を使いません。
SUM([売上])/COUNTD([オーダー日])
売上の合計をオーダー日のカウント(個別)で割ってね。
テキストで最大値のみを表示させて、答えを確認します。
Q8
Ord8(8) pic.twitter.com/XGRoPf56H6
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
まず、以下のパラメーターを作成します。
そして以下の式を行に追加します。
{EXCLUDE[カテゴリ1]:SUM(IF [カテゴリ1]=[ソート用カテゴリ] THEN [売上] END)}
カテゴリを無視して、もし、カテゴリがソート用カテゴリと一致していたら売上を出してね。名前は「ソート用売上」にします。
さらっとEXCLUDE初出しなので、ちょっとだけ説明します。

「A8メモ用」という名前で
SUM(IF [カテゴリ1]=[ソート用カテゴリ] THEN [売上] END)を行に入れてみます。
これはカテゴリがソート用カテゴリと一致していたら売上を出してねという式です
今、ソート用カテゴリでは家具になっているので、家具のみ売上の数字が出ています。
そして、家電、事務用品のためにNULL行ができました。しかし、この表はわかりにくいですよね。NULL行を取りたいと思います。
EXCLUDE計算はビュー内の除外したいものを指定することができます。
今除外したいのはカテゴリの区切りなので、上のような式になります。
ソート用売上を行に追加して、不連続、表計算の差にします。
パラメーターを表示させて、並び替えがうまくいっているか確認します。
ヘッダーを非表示にします。
Q9
Ord8(9) pic.twitter.com/B0gbe1Po6h
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
まず、顧客ごとの初回~最終購入日の差(月)を作成します。
{FIXED[顧客 Id]:DATEDIFF('month',MIN([オーダー日]),MAX([オーダー日]))}
顧客idごとに'月'単位で最初のオーダー日と最後のオーダー日の差を出してね。という式です。この式は
DATEDIFF('month',{FIXED[顧客 Id]:MIN([オーダー日])},{FIXED[顧客 Id]:MAX([オーダー日])})と同じ意味ですが、FIXEDでまとめて計算できるというわけですね!
ROUND([顧客ごとの初回~最終購入日の差(月)]/[顧客ごとの購入回数])
顧客ごとの購入回数はQ3で作りました。
ROUND関数は値を整数に丸めてくれる関数です。
この式の名前は「顧客ごとの購入間隔の平均」にします。
顧客ごとの購入間隔の平均を列に入れて、顧客数(顧客idのカウント(個別))と売上を行に入れます。それぞれテキストで最大値を表示させて、数値を確認します。
顧客数(顧客idのカウント(個別))に
WINDOW_MAX(COUNTD([顧客 Id]))=COUNTD([顧客 Id])を
売上に
WINDOW_MAX(SUM([売上]))=SUM([売上])を
それぞれ色に入れています。
Q10
Ord8(10)接続1/2 pic.twitter.com/fTMzJUXMoJ
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
カスタマーマスターを結合させます。
Ord8(10)接続2/2 pic.twitter.com/hw37Jwi3z1
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
都道府県リストを取得し(コピーする)、結合に入れます(ペーストする)
1行目が北海道/北海道になっているので、「フィールド名を自動に生成」をクリックします。
Customer_Masterの都道府県につなげたいのですが、都道府県リストには都道府県がまだないので、カスタム分割をして都道府県(/で区切った最後の1列)を取り出します。
そして結合式をコピーして、結合計算にペーストします。
そして、地方(/で区切った最初の1列)を取り出して、元のF1を非表示にします。
Ord8(10) pic.twitter.com/DJp9azHjsn
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
オーダー月ごとの顧客数(顧客idのカウント(個別))推移を出します。
[顧客ごとの初回購入日]=[オーダー日]
Q5で作成した顧客ごとの初回購入日を使います。
顧客ごとの初回購入日がオーダー日と一致していたら真、それ以外は偽というブール式を作ります。
この式を行に追加して、真、偽それぞれを別名の編集から新規、既存に名前を変えます。そして、新規のみを表示させます。
簡易表計算から顧客数を累計にして、地方を色に入れて回答を確認します。
(おまけ)
1位の地方を目立たせるために、1位の地方のみに色をつけます。
Ord8(10)おまけ pic.twitter.com/RLFZdygfWB
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
おなじみのWINDOW _MAX関数を使います。
WINDOW_MAX(SUM({FIXED[地方]:COUNTD([顧客 Id])}))=SUM({FIXED[地方]:COUNTD([顧客 Id])})
表内の地方ごとの顧客数の最大値が地方ごとの顧客数と一致していたら、真、それ以外は偽というブール式を作成します。
複数のデータソースを使って表計算(WINDOW _MAX)をする場合は集計集計である必要があるので、SUMは必要です。
この式を色に入れて、真のみに色をつけます。
表計算の方向を特定のディメンションで月と地方にチェックを入れます。
Q11
Ord8(11)1/2 pic.twitter.com/Kg7H0GFcVw
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
メーカー情報をブレンディングします。プライマリグループの作成から、メーカーを作成します。これは、同じデータベース内でないとLOD計算はできないからです。
サブカテゴリごとの割引率(平均)を棒グラフで出して、アナリティクスから0.15の定数線を入れます。
AVG([割引率])>=0.15
割引率の平均が15%以上なら真、それ以外は偽というブール式を作成します。
上の式を色に入れます。
Ord8(11)2/2 pic.twitter.com/1jgjheuTqM
— 動画掲載用 (@Kaodoramichan) 2021年1月8日
IIF({FIXED[サブカテゴリ1],[メーカー]:AVG([割引率])}>=0.15,[メーカー],NULL)
もし、サブカテゴリ、マーカーごとの平均割引率が15%を超えていたら、メーカーを返してね、それ以外はNULLねという式で、割引率が15%以上を出しているメーカーを特定します。ここのFIXED計算で、メーカーだけでなくサブカテゴリも入っている理由は、いくつかのメーカーは複数のサブカテゴリを持っているからです。名前は「割引率が15%超えているメーカー」
列に
INDEX()
を入れます。INDEX関数は行数を返す関数です。
アプライアンスから本棚まで1~17の数字が割り当てられています。
INDEX()の中に割引率が15%超えているメーカーを入れます。
これを割引率と二重軸にして、割引率を棒グラフにINDEX()を円にします。
INDEX()との重なりをなくすために、INDEX()の前に-(マイナス)をつけます。すると反対側に移動します。
表計算の方向を割引率が15%超えているメーカーに設定すると、円が綺麗に揃います。
円どうしの幅を縮めるために、軸の同期をし、0.005をかけます(この数字は適当です)
これで、割引率が15%超えているメーカーを出すことができたのですが、NULLも同時に出されているためNULLを除きたいです。単純にNULLを除外すると、割引率が15%超えているメーカーを持っていないサブカテゴリが全て消えてしまいます。そこで、割引率が15%超えているメーカーを色に入れて、色の判例からNULLを非表示にします。
割引率が15%を超えていないものの、割引率が15%を超えているメーカーを持っているサブカテゴリを確認します。
【Tableau】属性とは

自分がわかっていることだけをまとめました。
違う認識があったらぜひご教示くださいませ。難しい!
属性とは
上の図を見てください!ポケモンたちはそれぞれタイプを持っていますね。
ヒバニーが"ほのお"タイプ、ピカチュウが"でんき"タイプというように
それに対する値が1つの場合、その値を返します。
では、フシギバナのように"くさ"、"どく"とタイプが2つある場合はどうなるでしょうか。その場合は*(アスタリスク)が返されます。
・値が1つ→その値
・値が1つ以上→*(アスタリスク)
・NULLは無視される
○○に対して□□(属性)がいくつあるかを見ましょう!
上のポケモンの例で言うと、ピカチュウに対してタイプ(属性)がいくつありますか。答えは1つであり、その値の"でんき"です。
フシギバナに対してタイプ(属性)がいくつありますか。答えは2つであり、*です。
属性の切替

属性にしたいピルをクリックして、「属性」を選択します。
関数ATTR
属性に切替たピルをダブルクリックしてみると中身はこのようになっています。

属性にするときはこの関数ATTRで集計されています。
これを利用して、非集計の式を集計にする事もできます。
kaodora.hatenablog.com
属性の例①

カテゴリ、サブカテゴリごとの売上を出します。
サブカテゴリを属性にしてみます。
サブカテゴリが*になりました。
これは、カテゴリに対してサブカテゴリが複数あるからです。
では、カテゴリを属性にしてみます。

あれ、変わりませんね。
「サブカテゴリに対して家具がいくつあるか」という問いにしてみると簡単です。
1つしかないのでその値が返されているのです。
これは並び順を変えても同じ事です。
★属性でその値を返している例

北海道(地域)に対して、北海道(都道府県)は1つしかないので北海道を返しています。

では、カテゴリを属性にすることに意味はないのでしょうか??
属性の例②
次に地域、カテゴリ、サブカテゴリを置いて
カテゴリに対するサブカテゴリの売上の割合を出します。合計も入れます。
では、ここでカテゴリを属性にしてみましょう。
すると数字が変わりました。
合計を見てみると、地域に対するサブカテゴリの売上の割合になっています。
属性にするということは、ディメンションではなくなるということです。
ディメンションの役割を思い出すと、”区切る”というのがありました。
ここではカテゴリを属性にしたために、カテゴリで区切らなくなったのです。
つまりは、カテゴリで集計しないという事です。
属性は、その値を情報として持っていたいけど区切りたくない時に有効的です。
区切らずに”ラベル”のような役割を果たします。
つまずきポイント
なんとなくわかったけど、挟まれたときはどっちに対する属性なの?

これは「地域に対するカテゴリ(属性)」ですよね。地域に対するカテゴリは複数あるので*です。
さらに細かい粒度のサブカテゴリを入れると、「サブカテゴリに対するカテゴリ(属性)」になります。なぜ、「地域に対するカテゴリ(属性)」でなくなり*がなくなったのかと思いませんか?
先ほどの話を思い出してみると、属性にすると集計されなくなるのでしたね。ここでは新たにサブカテゴリというディメンションで集計をされてしまったので、カテゴリはただのラベルになって「サブカテゴリに対するカテゴリ(属性)」になりました。
ここがわかりにくいところです。
では、さらに細かくメーカーを入れてみます。
ここでも「サブカテゴリに対するカテゴリ(属性)」ですね。と思いきやの、これは「サブカテゴリ、メーカーというグループに対するカテゴリ(属性)」です。
カテゴリとサブカテゴリをひっくり返します。

ここも変わりません。「サブカテゴリに対するカテゴリ(属性)」です。「サブカテゴリ、メーカーというグループに対するカテゴリ(属性)」です。
ではサブカテゴリをとってみます。

「メーカーに対するカテゴリ(属性)」になりました。
つまりは属性は入れる並び順ではなくLevel Of Detail(データの粒度)に気を付けなくてはならないようです。
既にビューに存在する他のディメンション(LOD)、グループの属性が特定できる場合のみ、値が返ってくるのです。
難しい・・・。
属性の使用例
①値が同じかどうかチェックしたい時

サブカテゴリがメーカーに対していくつあるか調べます。
家具カテゴリのメーカー、HonとSafcoは*なのでサブカテゴリを複数持っている事がわかります。
メーカーとサブカテゴリ(ディメンション)をひっくり返してみると、確かにHonとSafcoは複数のサブカテゴリを持っています。
メジャーを属性にして値段が同じか調べたりもできそうですね。
②実績と予測をくっつける

これは売上の年推移を示し、さらに予測を追加した折れ線グラフですが予測と実績が離れていますね。
ここで、予測を属性にしてみましょう。
くっつきました。
実績に対して予測が1つしかないからです。
まとめ
属性は○○に対して□□(属性)がいくつあるか
・値が1つ→その値
・値が1つ以上→*(アスタリスク)
・NULLは無視される
属性になるとディメンションでなくなるため、”区切らず”に”ラベル”になる。
値の一致を確認したり、グラフを繋げたりする時に使う。

【Tableau】集計と非集計③~集計と非集計は混在できませんとは?~

だんだん慣れてきて、少し難しい計算式も書くようになりました。
と思っていたら

集計と非集計の壁にまたぶち当たってしまいました・・・
ここで克服したい・・・!
ズバリ!集計と非集計は混在できない
表題の通り、集計と非集計は混在する事ができません。
そもそも集計と非集計ってなんだったかを思い出すとシンプルです。
集計はまとめて計算してある(合計、平均など)もの、非集計は一行単位の値
でした。計算粒度が全く違うのでこれらを一緒に計算することはできません。
解決方法①集計か非集計どちらかに合わせる


(正しい利益率の求め方は上の方ですよ!)
解決方法②無理やり集計にする
このエラーが出てくるのはIF文を使うときが多いと思います。
では下の式はどうでしょうか。
カテゴリが事務用品だった場合の利益率を返して欲しいのですが、エラーになりました。利益率の中身は下のように、集計になっています。
利益率を非集計にする([利益]/[売上])と、正しい利益率とは言えないので
[カテゴリ]の方を集計にしなくてはなりません。
そこでよく使われるのは関数ATTRです。(=属性)
ATTRは式の値がすべての行で単一の値になっている場合は、式の値が返され、それ以外の場合はアスタリスク(*)が返されます。

有効な計算になりました!
解決方法③LOD計算、表計算を使う
計算式にするとLOD計算は非集計、表計算は集計になります。
例えば、サンプルスーパーストアのデータから2015年1月1日の製品数を取り出したいとします。上の例のようにATTRを入れてみても結果が出ません。

それでは、[製品id]をLOD計算にします。

今度はうまく出せました!
これはオーダー日が2015/01/01だったら、カテゴリ・オーダー日ごとの製品idのカウント(個別)を返してね、という式になります。
まとめ
LOD計算自体の説明はまたいつかどこかで説明できたらいいなと思います(不安)
とにかく集計と非集計が混在できないとTableauに言われたら、
- 集計か非集計に合わせる
- 属性で無理やり集計にする
- LOD計算や表計算を活用する
以上のことをして、サクサク解決しましょう!
 (ワンピース1000話おめでとう!)
(ワンピース1000話おめでとう!)
【Tableau】DATASaber:Performance Best Practice(Ord7)解説
はじめによんでください。 kaodora.hatenablog.com

全部書いてから気づいたのですが、内容盛り沢山すぎました!今後分けるか加筆するか何かしらしたいと思います。
パフォーマンスの考え方
どうしてパフォーマンスが大切か。
- フローが途切れる
- 本当のタスクを忘れる
- 答えを得るのに時間がかかる
- Fast workbook=Happy users
- 似たようなワークブックを量産せずに済む
- イライラする

パフォーマンスを決める要素

処理する場所

ベストプラクティス
- データが遅ければ、Tableauで早くなることはない
- Desktopで遅ければ、Serverで早くなることはない
- 入れすぎ厳禁(シンプルに)
今まではTableauが気持ちを汲み取ってくれたが
これからはTableauの気持ちを汲み取る!

Tableauの気持ちを聞く:パフォーマンス記録
ヘルプ→設定とパフォーマンス→パフォーマンスの記録を開始→(パフォーマンスの記録を停止)


データソース
データ量とパフォーマンスのジレンマ

対象データの件数
・レコード数
・行数が多いvs集計された行数が少ない
・フィルターを使用し、件数を削減(抽出フィルター、データソースフィルター)
リレーショナル・データベース
・インデックスとパーティショニングは有効
・インデックス
・表の結合キーの列
・フィルターで使用される例
・パーティショニング
・ディメンション項目
NULL
・ディメンション項目ではNULLを避ける
・NULLをなくしてインデックス効果を向上
DB側でテーブルを準備
・集計データを事前準備
・Tableauでの複雑な計算フィールドを回避するために、DB側に必要な値をテーブルに持たせておく
結合vsブレンディング
・結合
・(特殊な事情でなければ)同じデータベースであれば、表の結合が望ましい
・インデックスを有効利用
・1本のクエリ
・ブレンド
・レコード数が多く、表の結合に適さない場合
・集計ビュー
・結合&クロスデータベース結合
・ファクト(トランザクション)テーブルとマスタテーブルの結合
・ブレンディング
・多対多リレーションシップなどでJOINした際に値が合わないデータを結合
参照整合性の仮定
・ビューで使用している項目が1つのテーブルだけを対象とするケース
・「参照整合性の仮定」を設定することでクエリパフォーマンスを向上
・データメニューから設定
抽出vsライブ接続
・データエンジンの性能は相対的なもの
✔︎データエンジンが比較的速いケース
最適化されていないデータベース
PCファイル形式のデータソース
✔︎データエンジンが比較的遅いケース
高速マシーンのクラスター
データの抽出
・抽出のパフォーマンスの影響する原因
・行数
・列数(抽出ファイル作成時に影響)
・データ濃度(=ガーディナリティ、ディメンションメンバーの数)
・ディメンションvsメジャー
★集計された抽出
・集計された抽出を集計分析に使用
・DWHから負荷分散
・明細データはDWHに保持し、ライブ接続
・抽出を高速化
・表示単位に集計
・不要なディメンションフィルター
・使用していないフィールドを非表示
計算
・行レベル計算と集計計算
・データベース側で計算処理
・行レベル計算はスケーラビリティが高い
・DBチューニング施策が効果を出しやすい
・行レベル計算と集計計算の分割
・行レベル計算を1つの計算フィールドに
・集計計算を2つ目の計算フィールドに
・表計算
・クエリ結果を受け取り、Tableauが計算処理
・計算フィールドよりもTableauの計算負荷が高い
計算フィールドvsネイティブ機能
・ネイティブ機能は計算フィールドよりも速い事が多い
・ディメンションメンバーのグルーピング→グループが有効
・ディメンションメンバーの名前の変更→別名の変更
・メジャー値のカテゴリ化→ビンが有効
★計算フィールド
・データ型はパフォーマンスの影響が大きい
整数 < ブール
< ブール < 文字列
< 文字列
・ロジック計算にはブーリアンを使用する
・悪い例
IF[DATE]=TODAY() THEN "TODAY" ELSE "TODAY" END
・良い例
[DATE]=TODAY()
・文字の検索
・CONTAINTS()はFIND()より速い
・ワイルドカード照合はCONTAINTS()より速い
計算フィールドで読むパラメーター
・条件式で参照するパラメーター
・表示名を利用
・整数として計算ロジックで参照
 →
→ 
日付計算
そもそもデータ型を日付に変えればいい!文字型への変換は非効率
・悪い例
DATE(LEFT(STR([YYYYMMDD],4))+"-"+MID(STR[YYYYMMDD],4,2)0+
"-"+RIGHT(STR([YYYYMMDD],2)))
・数値型とDATEADD()の組み合わせ
・良い例
DATEADD('DAY',[YYYYMMDD]%100- 1,DATEADD('MONTH',INT([YYYYMMDD]%10000)/100)-1,DATEADD('YEAR',INT([YYYYMMDD])/10000)-1900,#1900-01-01#)
・日付関数
NOW() システムタイムスタンプ
TODAY() システム日付
ロジック関数
・ELSEIF!=ELSE IF
IF [REGION]="EAST" AND [CUSTOMER SEGMENT]
="CONSUMER" THEN "EAST-CONSUMER"
ELSE IF [REGION]="EAST" AND [CONSUMER SEGMENT]
<>"CONSUMER" THEN "EAST-ALL OTHERS"
END
END
・改善例
IF [REGION]="EAST" AND [CONSUMER SEGMENT]
="CONSUMER" THEN "EAST-CONSUMER"
ELSEIF [REGION]="EAST" AND [CONSUMER SEGMENT]
<>"CONSUMER" THEN "EAST-ALL OTHERS"
END
・更に改善
IF [REGION]="EAST" THEN
IF [CONSUMER SEGMENT]="CONSUMER"
THEN "EAST-CONSUMER" ELSE "EAST-ALL OTHERS"
END
END
フィルター
ディメンションフィルター
・不連続フィルターフィルターは遅い
・TableauはDBにクエリを発行し、全てのディメンションを取得しにいく
・範囲(連続)フィルターは速い
・大量の不連続の値を取り込むより速い
・データの濃度(ガーディナリティ*1列に入っている値の種類)が高い場合、
範囲フィルターの方が速い
・保持・除外フィルターは遅い
・複雑なWHERE句
・インデックスやパーティーションが有効に作用する
日付フィルター
・不連続日付
・ひとつひとつ取得しなければならないのでクエリ結果が遅い
・連続日付の範囲指定
・範囲で取得するのでクエリ結果が速い
・相対日付が更に速い(今日から1年前など)
クイックフィルター
・項目が表示されたクイックフィルターは遅い
・表示する必要のある項目は全て取得しなければならない
・複数の値(ドロップダウン)
・単一の値(ドロップダウン)
・数値フィルター
・範囲日付フィルター
・項目がデータに依存しないクイックフィルターは速い
・フィルターのための項目を探す必要がない
・複数の値(カスタムリスト)
・ワイルドカード照合
・相対日付フィルター
・期間を参照フィルター
クイックフィルターの表示項目
・2種のクイックフィルター表示方法
・データベース内のすべての値
・他のフィルターが変更されたとしても影響されない
・関連値のみ
・他のフィルターが関連してくる
⇨パフォーマンスvs ビジュアル/ナビゲーション
トレードオフの関係!!
ダッシュボードのフィルター
・大量のクイックフィルターは遅い原因
・たくさんのディメンションリストを取得しなければならない
・クイックフィルターの代わりにGuided Analyticsを活用する
・異なるディメンションレベルで複数のシートを作る
・フィルターアクションを活用する
クイックフィルターの代わりに・・・
・フィルターアクションを活用する!
メリット
・複数項目選択をサポート
・選択項目はデータに応じてダイナミックに変動
・データソース間を跨いでフィルターできる(最近クイックフィルターもできる・・)
・フィルター用のソースシートからもインサイトを得られる
デメリット
・設定がちょっと難しい
・UIがクイックフィルターやパラメーターの感じとちょっと違う
・ソースシートはデータソースからクエリされる必要がある
・パラメーターを活用
メリット
・フィルター項目表示用のクエリが不要
・データソース間を跨いでフィルターできる(最近クイックフィルターもできる・・)
デメリット
・単一項目のみしか選択できない
・パラメーター+計算フィールド=複雑になりがち
★フィルターの順序

ダッシュボードデザイン
ビュー(=シート)
・本当に必要なものだけを取得・表示する
・不要な"詳細"を外す
・チャート vs クロス集計
・行列の少ないマーク表示は表形式のものより早く表示できる
・テキストテーブルを描画するには大量のメモリが必要
・詳細なクロス集計を表示するにはGuided Analysisを使うこと
・不当な地理的役割は設定しない
・生成された緯度経度を参照する時間を省く
ダッシュボード
・シートやクイックフィルターを少なくする
・1シートにつき少なくとも1クエリ
・1クイックフィルターにつき少なくとも1クエリ
・タブを非表示にする(特にServerの場合)
・タブの表示されているビューはすべてプロセスが走る
・タブを表示するためにワークブックの構造を把握するプロセスが走る
・タブを減らすとパフォーマンスが上がる
・次のパラメーターを試してみる':tabs=no'
・フィルターアクションの"すべての値を除外"
・すべてのデータを取得する重たいクエリを避ける
・サイズを固定したダッシュボード
・異なるウインドウサイズで毎回描画しなければならない
・Viz QL Server はユーザーごとにレンダリングを行う
・"自動"はキャッシュヒット率が低い
・(それにそもそもデザインに問題もある)
Tableauの向き/不向き

【Tableau】DATASaber:Visual Best Practicell(Ord6)解説

Visual Best Practicellはこれが正解!というのはない気がしています。
ここで述べるのはあくまで個人的見解であることをご了承ください!
そして、問題を解くのにあたり「Viewで見たいもの」「Viewの悪い点」「Viewの改善点」を述べます。
改めてViewを言葉で説明する難しさを感じました・・・。
Q1
○Viewで見たいもの
各サブカテゴリの全体に対する売上の割合
○Viewの悪い点
色数が多すぎる
角度の違いを識別するのが困難
ラベルがどこに割り振られているか識別するのが困難
色の凡例とグラフの位置が遠い
タイトルが不明瞭→サブカテゴリの売上金額シェア
売上のサイズの凡例に意味がない
サブカテゴリの並び順に意味がない
(円グラフについてはVisual Best Practice lで述べています)
kaodora.hatenablog.com
①
○Viewの改善点
ツリーマップにして、売上の合計に対する割合を明確にする。
さらにカテゴリで分けることで、カテゴリ同士の売上の差を見ることもできる。
(But)ツリーマップは日本人が見慣れていないという欠点とともに、似たような四角の大きさのものはやはり数字を見る必要がある。また、ラベルが全て表示されるわけではない(オーバーラップなし)
②
○Viewの改善点
棒グラフで全体に対する割合を降順に並べた。
ラベルがわかりやすい。
(But)一部と全体の関係を表せていない。
Q2
○Viewで見たいもの
サブカテゴリごとの売上はそれぞれどの月に上がるのか、下がるのか
○Viewの悪い点
色数が多すぎる
線が重なってスパゲッティーのようになっている
意味なく同系統の色が使われている![]()
①
○Viewの改善点
面グラフにして、絡まりを解く。また、カテゴリで区切る。
(But)事務用品は数が多く、不明瞭である。
②
○Viewの改善点
ランクチャートにして、絡まりを解く。また、カテゴリに分ける。
(But)Viewで見たいものを見ることはできるが、あくまでランクであり明確な数字ではないので、どのくらい上がったか、下がったのかを見ることはできない。
Q3
○Viewで見たいもの
四半期ごとの売上の予算達成/未達成を見たい

○Viewの悪い点
棒の数が多すぎる
どちらが実績でどちらが目標なのか凡例を探し当てるまでわからない
異なる四半期の売上と目標金額を比較してしまう可能性がある
売上実績の時系列推移を見ることが困難
縦軸のラベル「値」に意味がない

○Viewの改善点
ブレットグラフにして、予算達成したものに色をつけた。
予算達成率を表示させる。売上推移も確認する事ができる。
Q4
○Viewで見たいもの
売上と利益の相関性を知りたい
○Viewの悪い点
行が多すぎてヘッダーが潰れている(白くなって表示できない)
売上と利益の相関を理解できない

○Viewの改善点
売上と利益の散布図を作成し、カテゴリに分ける。
Q5
○Viewで見たいもの
地域、サブカテゴリごとの利益を見たい。

○Viewの悪い点
画面の縦幅が十分でなく、縦棒グラフが圧迫されて棒グラフの長さが機能していない
地域のソート順に意味がない
縦軸の目盛り(ヘッダー)の桁数が多い
①
○Viewの改善点
横棒グラフにして、地域を北から南に並べる。
赤字の利益には赤色をつける。
各行を独立した軸範囲にして、同地域の中で比較しやすいようにする。
(But)しかし全体で利益の大小を確認することはできない。(棒グラフが潰れてしまう)
②
○Viewの改善点
ハイライト表にして、表示をK(千単位)に丸める。
インタラクションなしに、同じ画面内で利益の大小を確認する事ができる。
Prreatentive attributeの色相と彩度を組み合わせている。
Q6
○Viewで見たいもの
各地域のカテゴリ売上割合、カテゴリ別売上、年・地域・カテゴリ別売上を見たい。

○Viewの悪い点
地域・カテゴリ別売上マップは地域に分ける必要がなく、スクロールして見なければならず無駄なスペースになっている。
尚、カテゴリ別売上は色の凡例の役割を果たしている。
①
○Viewの改善点
地域・カテゴリ別売上マップを全国にする。
(But)一つ一つの円が小さく、それぞれのカテゴリ売上割合を見ることが困難
②
○Viewの改善点
地域ごとのカテゴリ売上割合を棒グラフで表し、カテゴリごとの売上年推移を折れ線グラフで表す。
Q7
○Viewで見たいもの
割引率と利益率の相関性を見たい

○Viewの悪い点
折れ線グラフが2本並んでいての、相関性がわからない。
①
○Viewの改善点
月ごとの割引率と利益率の散布図を作成する。
②
○Viewの改善点
月ごとの値を円にして、同じ月の値同士を線で結び、傾向線(多項)を引いた。
まとめ
データビジュアライゼーションは
- 目的、伝えたい内容
- 閲覧者が誰か(役職、役割、ビジュアライゼーションを読み解くスキル)
- 利用されるシチュエーション
- 表示される環境(画面サイズ、デバイスなど)
を考慮して作成する事が大切!
【Tableau】DATASaber:HandsOn-Intermediatell(Ord5)解説
はじめによんでください。

Q1
Ord5(1) pic.twitter.com/A5Uid9KqOW
— 動画掲載用 (@Kaodoramichan) 2020年12月30日
カテゴリ、サブカテゴリごとの売上を出します。
そして以下の式で売上を分類します。
IF SUM([売上])>=20000000 THEN '2000万円以上'
ELSEIF SUM([売上])>=10000000 THEN '1000万円以上'
ELSEIF SUM([売上])>=5000000 THEN '500万円以上'
ELSE '500万円以下'
END
もし、売上が2000万円を超えていたら'2000万円以上'と返してね
そしてもし売上が1000万円を超えていたら'1000万円以上'と返してね
そしてもし売上が500万円を超えていたら'500万円以上'と返してね
それ以外は'500万円以下'と返してね,そいう式です。
「売上区分」という名前をつけます。
売上区分を行に追加したら完成です。
おまけ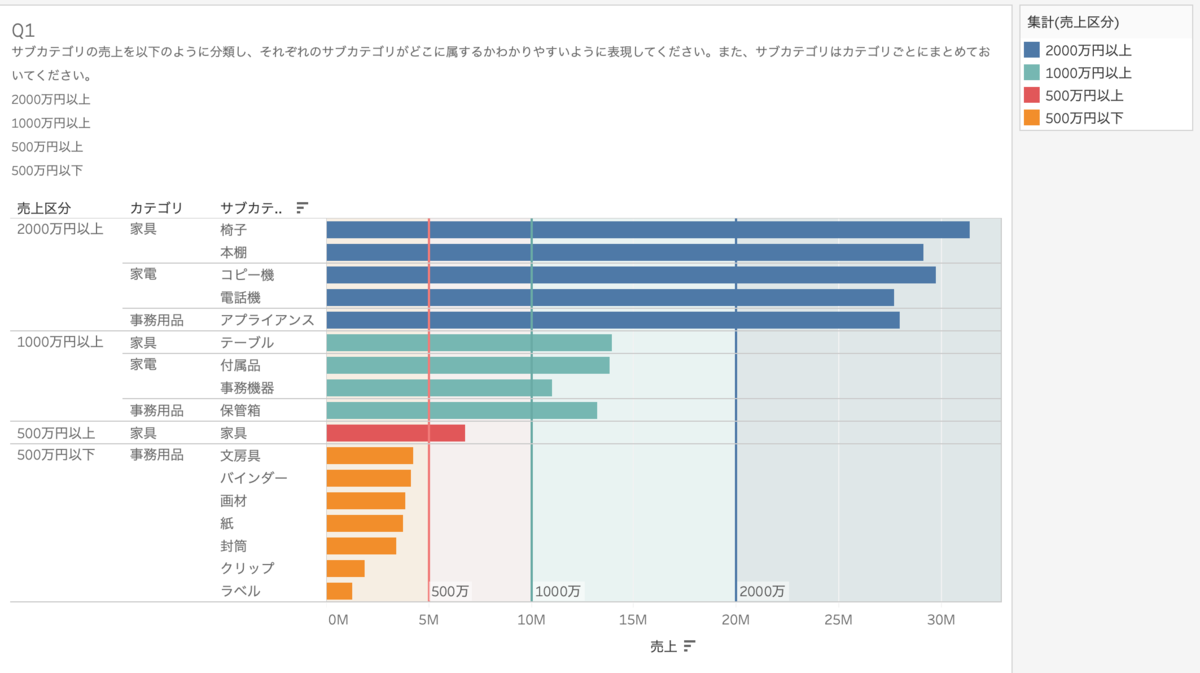
Ord5(1)おまけ1 pic.twitter.com/AXskqBU9el
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
500万、1000万、2000万それぞれに定数線を追加して、それぞれ色を設定します。
おまけ2
Ord5(1)おまけ2 pic.twitter.com/NsFyCdbUUW
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
サブカテゴリごとの売上を円の大きさで出します。
先ほど作成した売上区分を行に、カテゴリを列に入れます。
カテゴリごとに色をつけて、サブカテゴリをテキストに入れます。
書式設定方グリッド線を追加して完成です。
Q2
Ord5(2) pic.twitter.com/tb4mNqt0rb
— 動画掲載用 (@Kaodoramichan) 2020年12月28日

上のようなパラメーターを作成します。
そして以下のような式を、行の売上と利益の代わりに入れます。
IIF([売上・利益切替]=1,[売上],[利益])
もし、[売上・利益切替](先ほど作ったパラメーター)が1だったら(売上)、売上を返してね、それ以外は利益を返してね。という式です。
ダッシュボードで3つのワークシートを配置して、パラメーターを表示させます。この時、単一の値のリストにします。
Q3
Ord5(3) pic.twitter.com/VJRQhmpHxB
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
まずは利益からビンを作成します。
ビンのサイズからパラメーターを作成します。(事前に作っておいてここで選択することもできます。)
(5000~20000を5000ごとに切り替えられる)
作成したビンを列に、オーダーid(個別のカウント)を業に入れます。
10000ごとのビンで最大値をテキストで表示させます。
WINDOW_MAX(COUNTD([オーダー Id]))=COUNTD([オーダー Id])
ビンにおけるCOUNTD([オーダー Id]の最大値が、COUNTD([オーダー Id]と一致していたら真。という式を色に入れます。
すると最大値のビンのみ色をつけることができます。
Q4
Ord5(4) pic.twitter.com/7CQ4xmyQZz
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
顧客(顧客名)ごとの数量と利益の散布図を作成します。
列と行にそれぞれ地域とカテゴリを入れて、傾向線を追加します。
今回は傾向に着目したいので、一つ一つの円は最大に小さくします。
明らかに数量が多い時に利益は高い傾向にあるのは四国のようです。
Q5
Ord5(5) pic.twitter.com/vU4WHVqOSh
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
カテゴリごとの売上を出して、顧客区分を色に入れます。
表計算の「合計に対する割合」を表(下)で出します。それから、テキストを表示します。
Q6
Ord5(6) pic.twitter.com/C7ficGw5o9
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
2016年の顧客ごとの売上を出します。カテゴリをフィルターに入れて、単一のリストでそれぞれを切り替えられるようにします。
顧客名をフィルターに入れて、条件を[売上]>=200000に設定します。
しかし、シートを見ると20万円以下の顧客も表示されています。
それは、フィルターに優先順位がつけられていないからです。
Tableauには上の図のように、フィルターの順番があります。(クエリパイプライン)
今フィルターには、3つの同列のディメンションフィルターが混在してます。
今表示されているのは、20万円以上買った顧客が2016年に家具を買った顧客ごとの売上なのです。
今見たいのは、2016年に家具を20万円以上買った顧客ごとの売上ですよね。
「2016年」「家具」を先にフィルターをかけたいので、それぞれをコンテキスフィルターに追加します。すると図のように、ディメンションフィルターよりも先にフィルターをかけることができるようになります。
Q6別解
Ord5(6)別解 pic.twitter.com/SSs9PnHgND
— 動画掲載用 (@Kaodoramichan) 2020年12月30日
2016年の顧客ごとの売上を出します。カテゴリをフィルターに入れて、単一のリストでそれぞれを切り替えられるようにします。
売上をフィルターに入れて、200000~に設定します。
上の図のようにメジャーフィルターはディメンションフィルターよりも後にかけられます。
Q7
Ord5(7) pic.twitter.com/q6lUt0oSgk
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
地域、サブカテゴリごとの売上を出します。
売上を表計算からサブカテゴリのランクを出して、不連続にします。
ランクを行に入れます。
また、ランクを連続にしてフィルターに入れます。(連続だとスライダーにできる)
そこで3に絞り、サブカテゴリのハイライターを表示させて全ての地域に存在するサブカテゴリを確認します。
また、スライダー上の数字を自由に変えることができます。
Q7別解1

Ord5(7)別解1 pic.twitter.com/BufzEZvL1C
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
地域、サブカテゴリごとの売上をクロス集計で出します。
それから、チャートを四角にして、テキストの表示をサブカテゴリのランクにします。
テキストの配置を調節して、ツールバーを「高さを合わせる」にします。
連続にしたランクをフィルターに入れて表示させ3に絞ります。
Q7別解2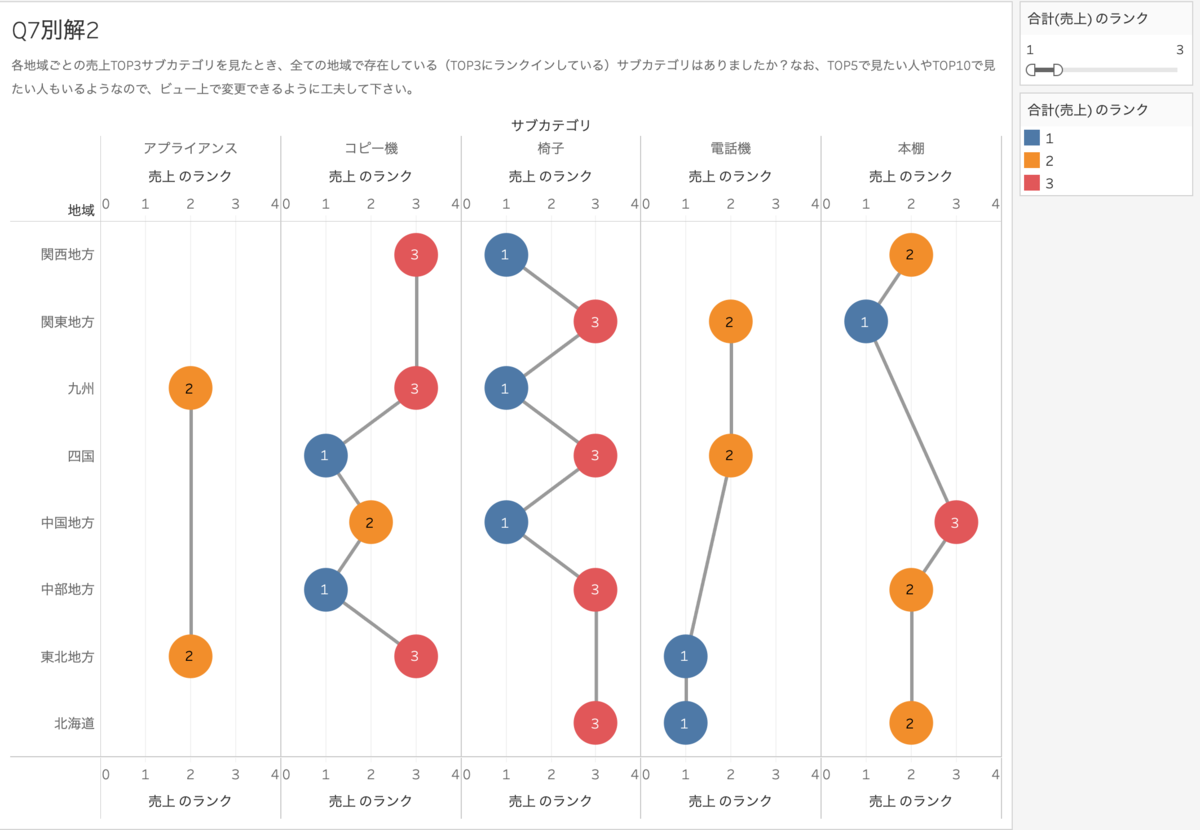
Ord5(7)別解2 pic.twitter.com/kRZ6EG3Vkb
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
地域、サブカテゴリごとの売上を出します。
サブカテゴリのランクにして、それを複製します。片方を円に、もう片方を線にしてこれらを二重軸にします。
ランクをフィルターに入れて、3に絞ります。
円のサイズを大きくして、ランクの数字を表示させます。ランクを色に入れます。
Q8
Ord5(8) pic.twitter.com/ceJqP4oCQG
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
ダッシュボードのアクションから、フィルターを作成し以下のように設定します。

(ダッシュボードQ8を選択したら、ダッシュボード明細表を表示する)
Q9
Ord5(9) pic.twitter.com/9AtCHrMZGU
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
週ごとの売上を出します。
簡易表計算の移動平均を前12週に設定します。
月ごとの傾向を見たいので、色に月を入れるのですがそのまま入れると別れてしまいます。一連の流れの中での、各月の傾向を見たいのでまず連続にします。
DATEPART('month', [オーダー日])
DATEPART関数は、指定した単位の数字を返します。そして日付関数ではなくなります。ここでは、月の数字を返します。
上の式を色に入れても、思ったようにいきません。
それは、ここでは数字を合計で返されているからです。(1月5日週の場合、その週のオーダー回数分1が足されている)
そのため、この式を中央値にします。(最大値、最小値でもOK)
1が何回足されても、1の数字の羅列の中で中央値(最大値、最小値)は1なので、それぞれの月を出すことができます。
これを不連続にして、色の関連をなくします。
11月は売上の大きい傾向になるようです。
Q10
Ord5(10) pic.twitter.com/TN8EpNagxd
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
2014年の製品名ごとの売上を出します。
売上をフィルターに入れて、20万円以上にします。
売上を簡易表計算のランクにして、不連続にします。それから行に入れます。
ランクが行番号のような役割を果たして、一目で数を知ることができます。
Q11
Ord5(11) pic.twitter.com/NzALPwdGK6
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
サブカテゴリごとの売上(非集計)を出します。
円チャートにして、アナリティクスペインから箱髭図を追加します。明細単位の売上はテーブルが一番大きいようです。
オーダーid(個別のカウント)を行に追加して、サブカテゴリごとのオーダー回数を見ます。テーブルのオーダー回数は他のサブカテゴリと比べてもそんなに多くなさそうです。
Q12
Ord5(12)1/2 pic.twitter.com/R8vzxg9xnK
— 動画掲載用 (@Kaodoramichan) 2020年12月30日
まず、以下のパラメーター2つを作成します。
「シュミレーション対象カテゴリ」
「売上%増加」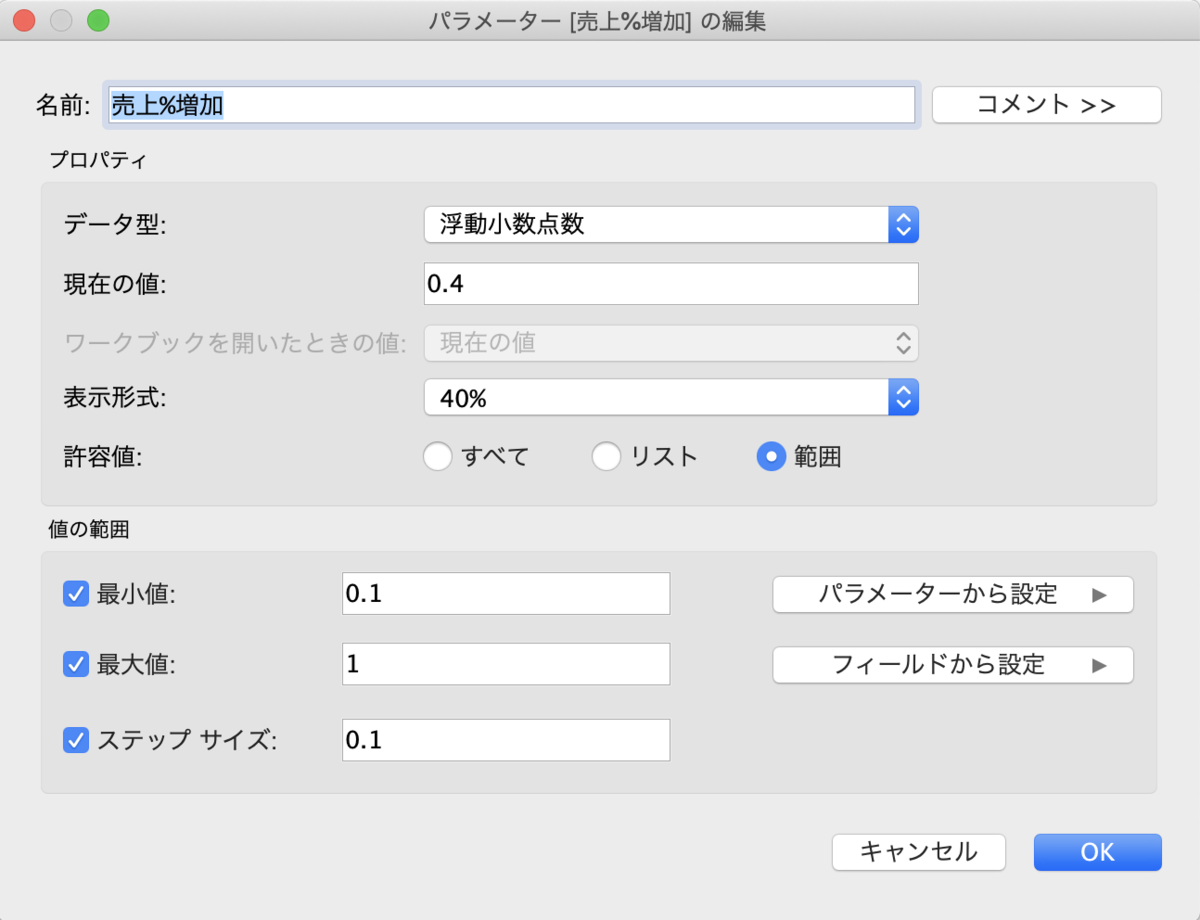
そして、作成したパラメーターを元にした式を作成します。
IIF([カテゴリ]=[シュミレーション対象カテゴリ],[売上]*(1+[売上%増加]),[売上])
もし、カテゴリが[シュミレーション対象カテゴリ](パラメーター)と同じだったら、
売上×(1+[売上%増加](パラメーター)),[売上])を返してね、それ以外は売上を返してね
という式です。
「売上*%増加」という名前にします。
地域を列に、売上*%増加を列に入れます。
Ord5(12)2/2 pic.twitter.com/1q7bGbSE04
— 動画掲載用 (@Kaodoramichan) 2020年12月30日
フィルターで2016年に絞ります。
売上を詳細に入れて、リファレンスラインの追加から分布を追加します。
100,110で設定して、下を塗り潰しにします。
2つのパラメーターを表示させます。
「売上%増加」の表示をパーセンテージにします。
SUM([売上*%増加])>=SUM([売上])*1.1
[売上*%増加]がSUM([売上])*1.1より大きかったら真という式を作成します。
上の式を色に入れます。
そして全てのカテゴリで検証します。
Q13
Ord5(13) pic.twitter.com/u6U6SG8eTQ
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
ダッシュボードでWebページを追加し、指定のWebサイトを入力します。
ダッシュボードのアクションからURLに移動...を設定します。
ダッシュボードQ13を選択すると、http://www.google.com/search?qで<製品名>を検索します。
URLで、URLを入力して▶︎から<製品名>を入れます。
URLをターゲットで、Webページオブジェクトにすると先ほど設定したWebサイト上でURLを表示させることができます。
Q14
Ord5(14) pic.twitter.com/nLcXoAafDa
— 動画掲載用 (@Kaodoramichan) 2020年12月28日
四半期ごとの売上を出します。
出荷モードを色に入れます。
アナリティクスペインから予測を追加します。
予測を属性にすると、売上推移と予測を繋げる事ができます。属性は区切らずに情報として持っておきたい場合に使えます。
Q15
Ord5(15) pic.twitter.com/YsvTlpeXMf— 動画掲載用 (@Kaodoramichan) 2020年12月28日
サブカテゴリごとの数量と利益の散布図を作成します。
カテゴリを色に入れます。
オーダー(年)をページに入れて、すべての末尾に履歴を表示させます。
そして、再生ボタンをクリックすると家具の椅子が2015年まで数量、利益ともに好調であった事がわかります。残念ながら2016年では落ちています。