【Tableau】データ接続の種類~完全版(たぶん)~

突然ですがデータ接続うまくいってますか!
初心者の時って結局どうやって繋げばいいのかあやふやですよね。私は今もあやふやですハハハ
まずはこれを見てください!
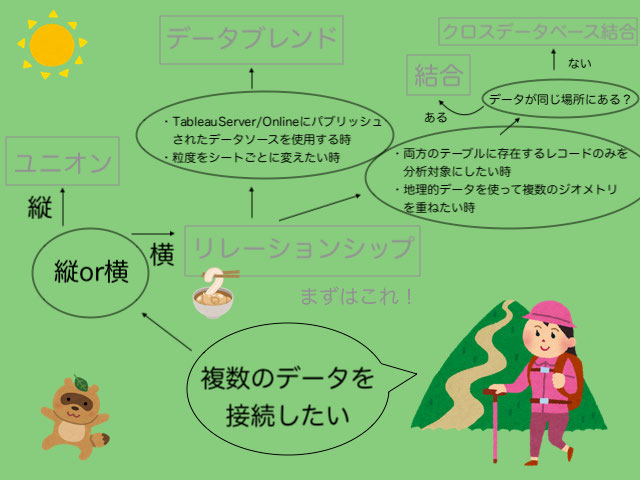
まずはこれを見て今ご自身が繋げたい状況を確認してみてください!
この記事ではそれぞれの説明をざっくりしています!概要、どんな時に?、作り方、注意点で分けています。
結合
結合とは、データを(非集計で)横に繋げるものです!
◯どんな時に?
以下のように、共通のフィールドがありそれぞれ横に繋げたい時は結合を使います。
◯作り方
— 動画掲載用 (@Kaodoramichan) 2021年2月17日
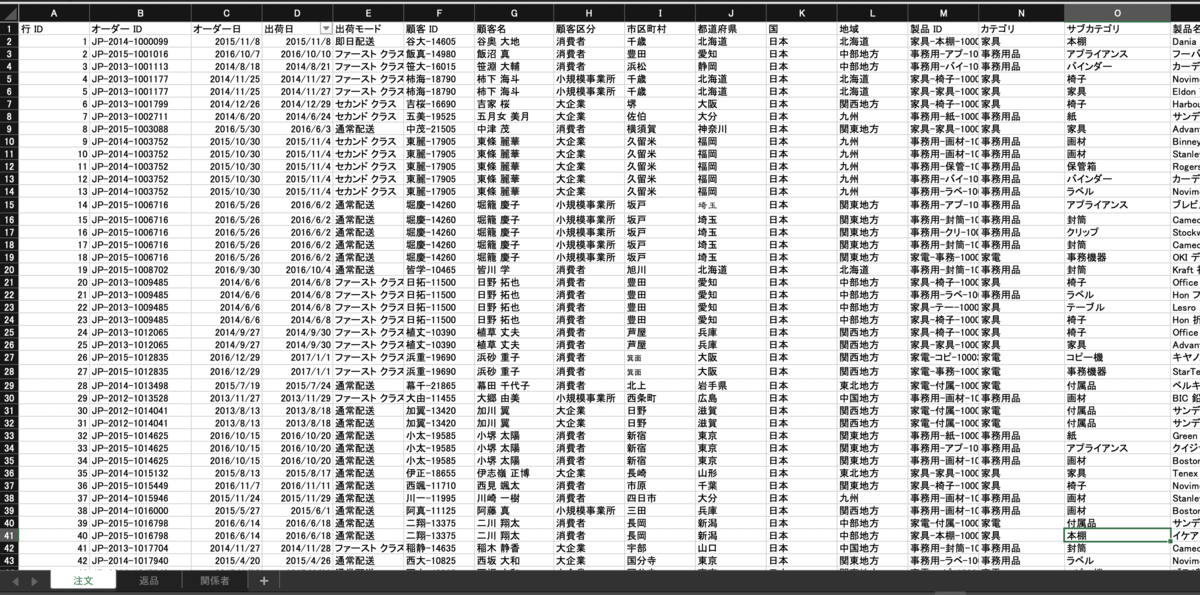
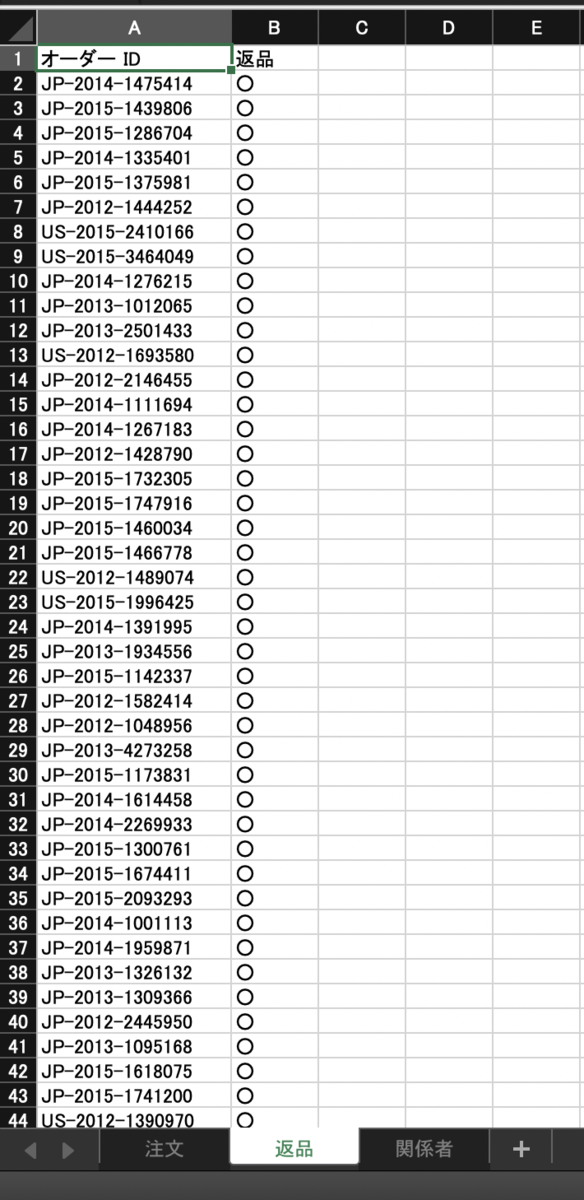
まず、注文シートをドラッグ&ドロップした後ダブルクリックをします。
それから、返品シートをドラッグ&ドロップします。
オーダーidという共通のフィールドで結合されて、「オーダーid(返品)」「返品」というフィールドが追加されます。
ビュー上では以下のように表示されます。
◯結合の注意点
①両方のデータに共通のフィールドがなくてはいけない。(自分で指定することも可能)
データの型は同じでなくてはならない。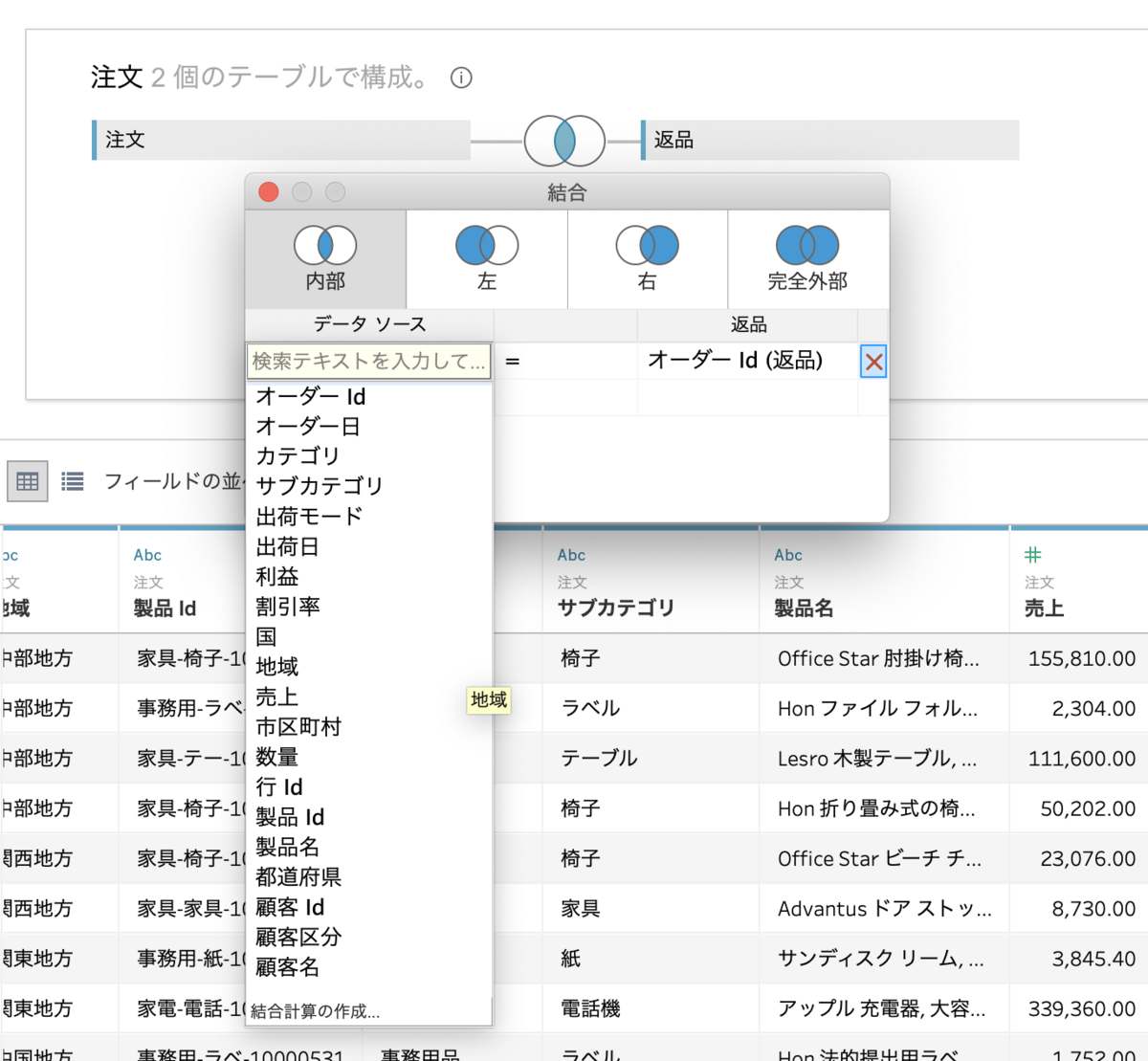
②両方のデータは、同じファイル内になくてはいけない。 (こんな感じ!)
(こんな感じ!)
③⚠︎データ同士が1:1出ない場合は、重複して計算され正しい値にならない
私はここがピンと来なくてなあなあにしてたので丁寧に説明しますね。
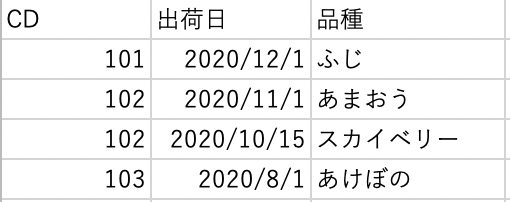
上の2つのシートを結合したいです。すると以下のようになりました。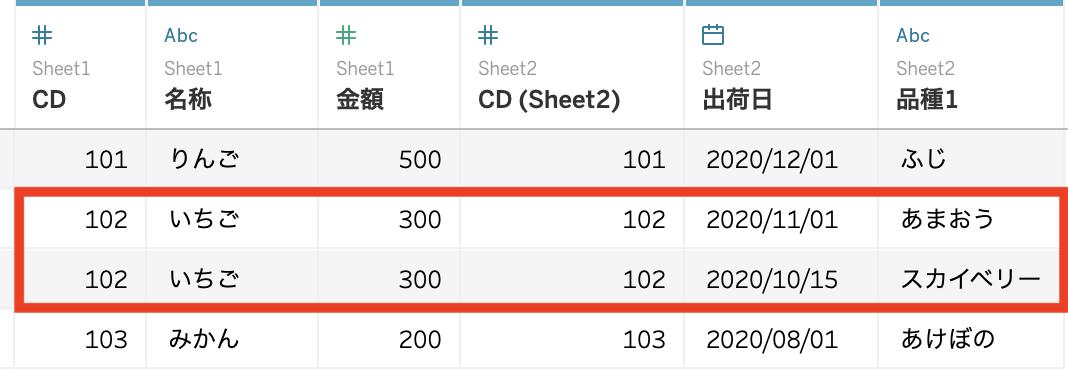
CDで結合するといちごが複数の品種と関連づけられているため、いちごの金額が2回以上カウントされています。
名称ごとの金額を出すと2回カウントされているため、いちごの値段が二倍になってしまっています。
(*)この問題はFIXED計算で回避することができます。
{FIXED[名称]:MAX([目標売上])}
クロスデータベース結合
クロスデータベース結合と結合は(非集計で)横につなげるという点でほとんど同じです。違う点は、繋げるデータが同じファイル内にないという点です。
◯どんな時に?
以下のように、違うファイルのものを横に繋げたい時はクロスデータベース結合をします。ExcelとCSV、データベースとExcelというようにデータ形式が違っていても結合することができます。

◯作り方
クロスデータベース結合 pic.twitter.com/jI9OCIgUs6
— 動画掲載用 (@Kaodoramichan) 2021年2月17日
まず、シートをドラッグ&ドロップした後ダブルクリックをします。
それから、繋げたいシートをドラッグ&ドロップします。
CDという共通のフィールドで結合されて、「出荷日」「品種」というフィールドが追加されます。
または、追加をクリックしてファイルを選択することができます。
ビュー上では以下のように表示されます。
◯クロスデータベース結合の注意点
結合の注意点と同じ内容なので詳細は割愛させていただきます!
①両方のデータに共通のフィールドがなくてはいけない。(自分で指定することも可能)
データの型は同じでなくてはならない。
②データ同士が1:1出ない場合は、重複して計算され正しい値にならない
データブレンド
データブレンドとは、複数のデータをそれぞれ集計してから横に繋げるものです。同じファイルにあっても、違うファイルにあってもデータブレンドは可能です。結合、クロスデータベース結合との違いは、集計してから繋げるか一つ一つを(非集計で)繋げるかです。
なんだかよくわからないなぁ
とここでつまずかれる方多いのではないのでしょうか!丁寧すぎるくらいご説明します😤
結合とデータブレンドの違い
結合とデータブレンドの違いは一言で言えば
繋がってから集計する→結合
集計してから繋がる→データブレンドです!
以下のようなファイルを繋げたいとします。
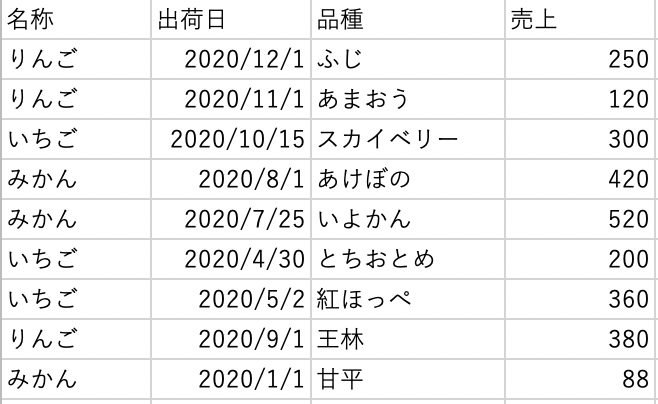
これを結合すると、非集計で繋げるということになります!以下は結合した結果です。先ほど、結合の注意点としてデータ同士が1:1出なければ複数カウントされてしまうのでしたね。これも、目標売上が複数カウントされていますので、間違った結果になります。
目標売上と売上を並べると、複数カウントされている分目標売上の数字が間違ったものになっていますね。
ではここでデータブレンドしてみましょう。データブレンドはそれぞれ集計してからくっつくのでした。
目標売上と売上を並べると、正しい数字になりました!
あれ!データブレンドの方がいいことづくめじゃない!?
そう思いがちですが、良し悪しなので違いをしっかり抑えましょう〜!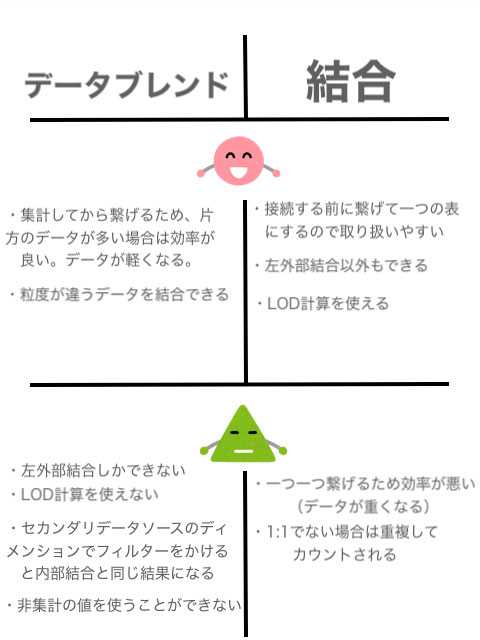
ではデータブレンドの話に戻ります!
◯どんな時に?
上の例のように粒度が違うデータを結合するとき!逆に言えば、一個一個繋ぐことができない時。
◯作り方
①
データブレンド pic.twitter.com/DbdhwlaPp6
— 動画掲載用 (@Kaodoramichan) 2021年2月17日
 をクリックして、新しいデータソースを追加します。
をクリックして、新しいデータソースを追加します。
②
データブレンド② pic.twitter.com/R0K58gTUqK
— 動画掲載用 (@Kaodoramichan) 2021年2月17日
シートを開いて、ファイルをドラッグ&ドロップします。
(データソースの編集画面でドラッグ&ドロップすると結合になってしまう)
ビュー上では以下のように表示されます。
◯データブレンドの注意点
①両方のデータに共通のフィールドがなくてはいけない。(自分で指定することも可能)
データの型は同じでなくてはならない。また、シートごとにどのデータを繋げるか選択することができ、この点でデータブレンドは柔軟であると言えます。
共通のフィールドが鎖で繋がれていることを確認してから使いましょう→
鎖が繋がれていない状態で複数のデータを使うと以下のような警告が出ます。
フィールド名が同じであれば、自動的に鎖は繋がりますが、異なる場合は自分で設定する必要があります。
- フィールド名を揃える
フィールド名を揃える pic.twitter.com/StLqMUIHdr
— 動画掲載用 (@Kaodoramichan) 2021年2月17日 - ブレンドリレーションシップの編集をする
ブレンドリレーションシップの編集をする pic.twitter.com/W0QNCJmT6e
— 動画掲載用 (@Kaodoramichan) 2021年2月17日[データ]→[ブレンドリレーションシップの編集]から編集する。
②左外部結合しかすることができない。よって、右側にしかないデータは結果に出てきません。プライマリデータソースに対してセカンダリデータソースが左外部結合します。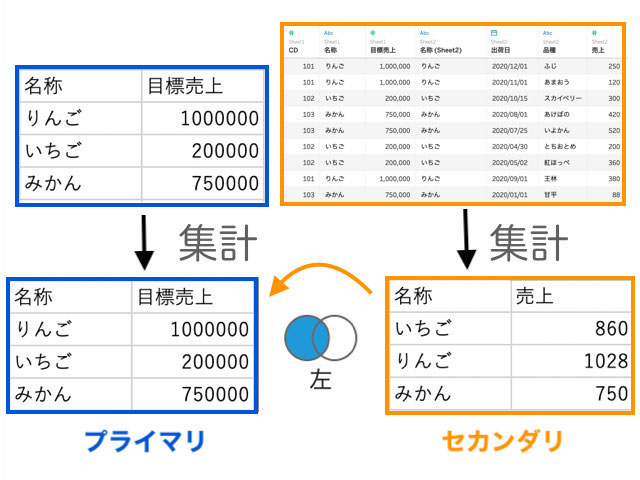
プライマリとセカンダリってどうやって決まるの?
というところですが、フィールドに入れた順です。下の動画を見てください。
プライマリとセカンダリ pic.twitter.com/Ah8IyAwTDL
— 動画掲載用 (@Kaodoramichan) 2021年2月17日
③セカンダリデータソースのディメンションでフィルターをかけると内部結合と同じ結果になる。
④非集計の値を扱うことはできない
⑤非集計で計算することはできない
ここまでくると当たり前のような気もしますが、集計されてからくっついているデータブレンドでは非集計(1行単位)にバラして計算することはできません。
集計と非集計の定義が曖昧な方は確認してください〜
リレーションシップ
「なんか最近出たらしい便利そうなやつ」というイメージとは今日でおさらばしましょう!👋

リレーションシップはその形から「Noodle」と呼んでいる人がいるそうです。(突然の余談)
同じファイルにあっても、違うファイルにあってもデータブレンドは可能です。
上のデータをリレーションシップしてみましょう。以下のようになりました。
リレーションシップの編集を見ればわかるように、結合を指定しなくてもTableauが適切な結合を考えてくれます。( こういうやつ)
こういうやつ)
そして、表を見ればわかるようにそれぞれの表は独立し、先に結合表を作りません。
今までの結合では以下のような結合表を作り、
目標売上と売上を並べると、複数カウントされている分目標売上の数字が間違ったものになりましたね。
しかし、リレーションシップでは重複行をカウントせず正しい数字を出すことができます!
では、リレーションシップでは結合を選択しないと言いましたが、外部結合はどうでしょうか。 
データブレンドでは左結合しかできないため、この場合以下のようにぶどうは表示されません。
しかし、リレーションシップでが以下のようにぶどうが表示され(目標金額はないので空欄となる)外部結合をすることができます。

また、現在のビジュアライゼーションで使用されているフィールドを持つテーブルのデータに対してのみ、クエリが実行されます。
要はTableauが適切な結合を考えてくれる便利な接続方法です。
◯どんな時に?
結合やデータブレンドと同じようにデータを横に繋げたい時です。
集計されてから繋がるというわけではないという点結合に近いですが、重複行をカウントしないという点ではデータブレンドに近いですね。データブレンドでは、LOD計算できなけどリレーションシップではできるし。
なんのこっちゃ。結合とデータブレンドのいいとこどりですね。
複数のデータを繋げたい時、まずはリレーションシップを検討してみましょう。
逆に!リレーションシップでない方がいい時はどんな時でしょうか。
①両方のテーブルに存在するレコードのみを分析対象にしたい時→結合
結合なら最初にINNER JOINするだけで済みますが、リレーションだとフィルターを追加する必要があります。
②地理的データを使って複数のジオメトリを重ねたい時→結合
リレーションではIntersectsを指定できません。
③TableauServer/Onlineにパブリッシュされたデータソースを使用する時→ブレンド
パブリッシュされたデータソースは別のデータソースの中に論理テーブルとして追加することができず、リレーションを組むことができません。
(*)また、リレーションは結合粒度を最初に指定するので、シート上でそれを変更することができません。ブレンドはマージする粒度をシートごとに変えたり、リンクフィールドに計算式を指定したり出来るので、そのあたりの柔軟性があるとも言えます。
(出典:https://community.tableau.com/s/group/0F94T000000gQZwSAM/japan)
◯作り方
リレーションシップ pic.twitter.com/L9ENeK8pqm
— 動画掲載用 (@Kaodoramichan) 2021年2月19日
データソース編集画面にシートをドラッグ&ドロップします。
それから、繋げたいシートをドラッグ&ドロップします。それから共通のフィールドを指定します。
以下のようにシートはそれぞれ独立しています。
シートはそれぞれ独立している。 pic.twitter.com/QtTH7Fegr1
— 動画掲載用 (@Kaodoramichan) 2021年2月19日
ビュー上ではこのように表示されます。
◯リレーションシップの注意点
①両方のデータに共通のフィールドがなくてはいけない。(自分で指定することも可能)
データの型は同じでなくてはならない。
②TableauServer/Onlineにパブリッシュされたデータソースを編集することはできません。
ユニオン
ユニオンとは、ずばりデータを縦に繋げるものです!
◯どんな時に?
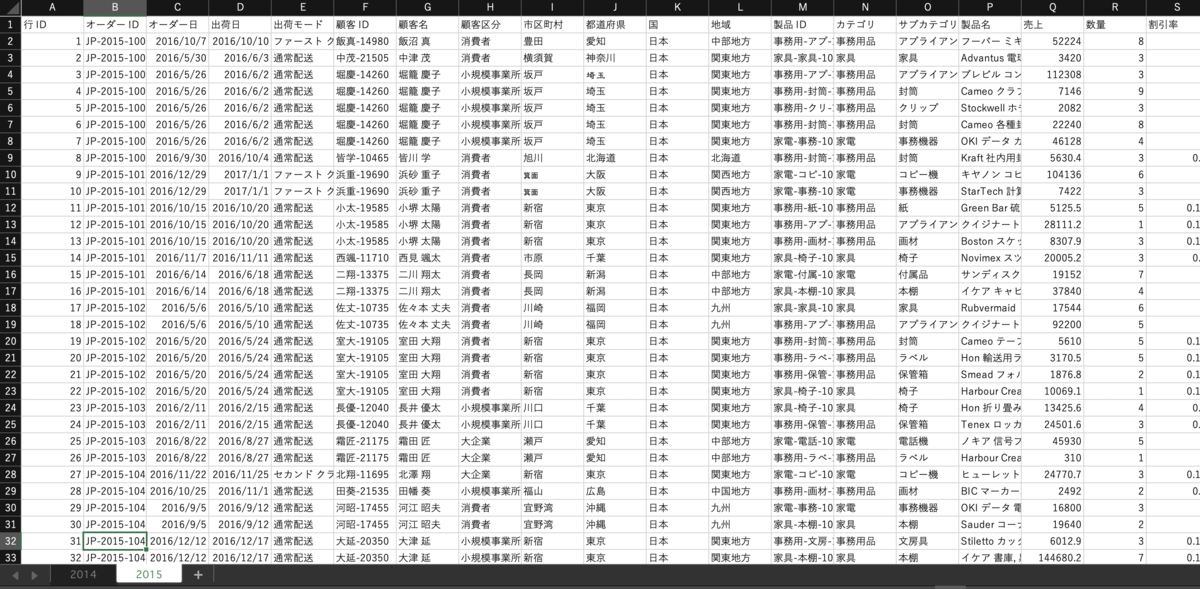
以下のように、データの項目は同じで
同じブック内で、年や月でシートが分かれているデータはありませんか。
この場合は年が違うだけですので、縦に繋げたいところですよね。
ここでユニオンを使います。
Tableauに入れるとこんな感じになります。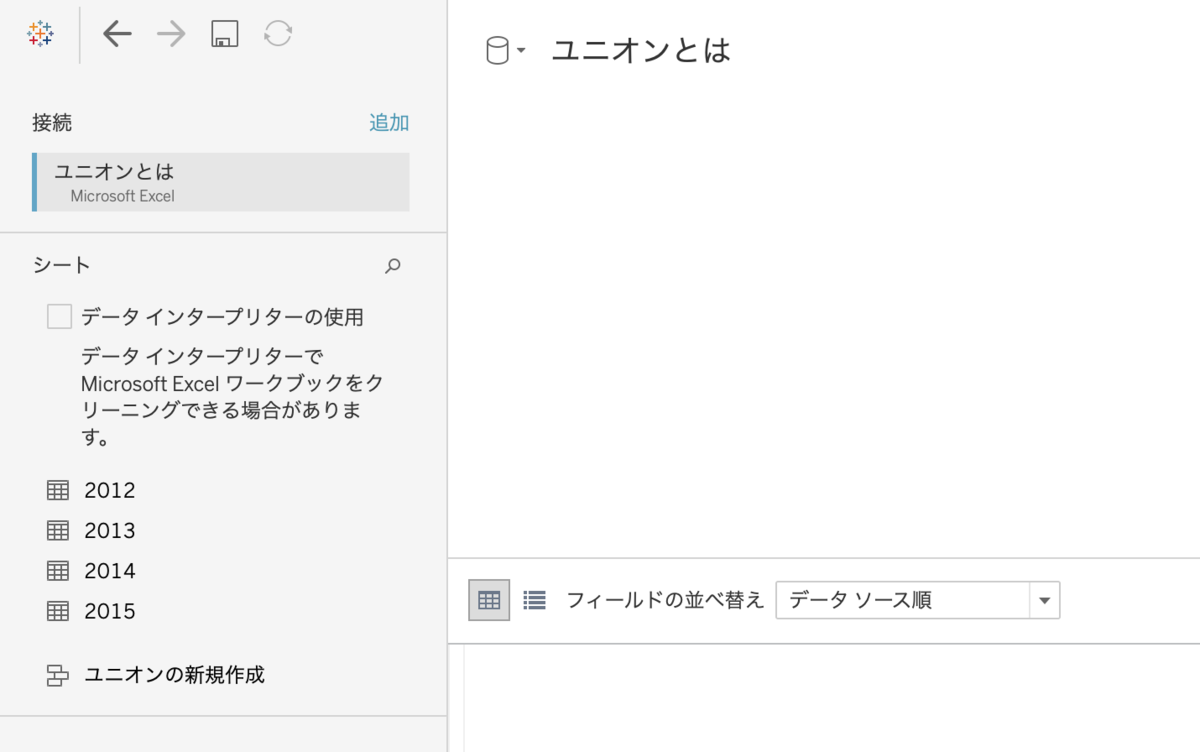
◯作り方
①
ユニオンの作り方① pic.twitter.com/fy0SKMYH6M
— 動画掲載用 (@Kaodoramichan) 2021年2月9日
②
ユニオンの作り方② pic.twitter.com/Z3qjHo3R9X
— 動画掲載用 (@Kaodoramichan) 2021年2月9日

ユニオンにすると、「Sheet」「Tablea Name」というフィールドが自動的に作成されます。
作成されたユニオンをダブルクリックして、さらに▼をクリックすると「ユニオンの編集」から編集することができます。
◯ユニオンの注意点
①両方のデータは、同じファイル内になくてはいけない。 (こんな感じ!)
(こんな感じ!)
②両方のデータは、フィールド名が同じでなくてはいけない。データの型は同じでなくてはならない。
*しかし、もし以下のように違っていても、「一致していないフィールドをマージ」することで解決することもできます。

ここでは、注文日とオーダー日というようにフィールド名が違いますね。
しかし、同じ内容なのでマージしたいと思います。
一致していないフィールドをマージ pic.twitter.com/k4QYQKYASU
— 動画掲載用 (@Kaodoramichan) 2021年2月9日
一つのフィールドにすることができました!ヤッタネ。
【Tableau】セットとは!~グループとの違い~

1.セットとはなんでしょうか!
セットとはディメンションから作られる、ある条件でIN/OUTの2つに分けるものです。
実際にセットを作ってみます。
製品名の売上TOP10をチェックしたい!
こんな時は、どうしますか!
製品名を行に入れて、売上を列に入れて、降順にして・・・
製品名をフィルターに入れて、条件で売上上位10に設定します。
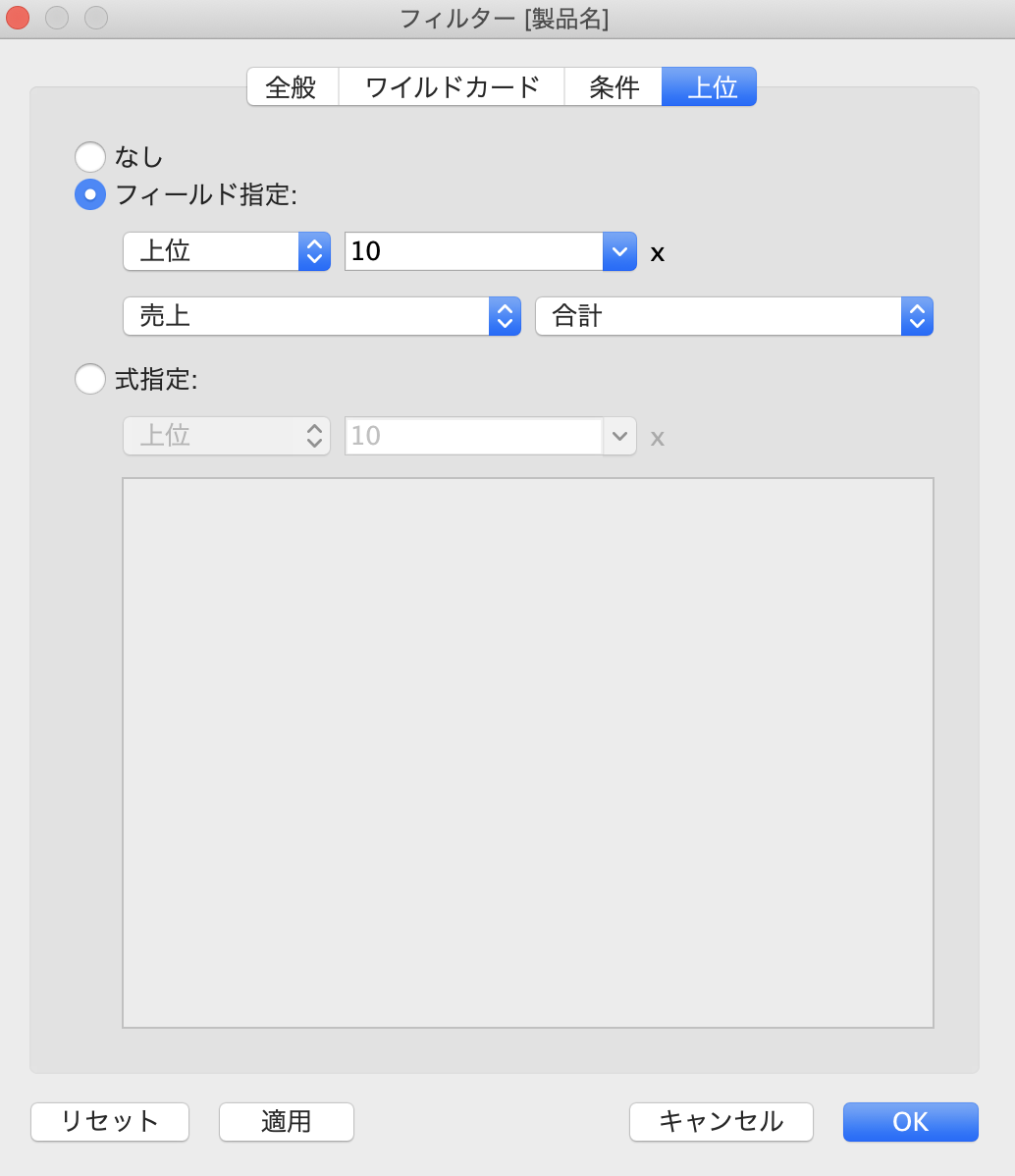
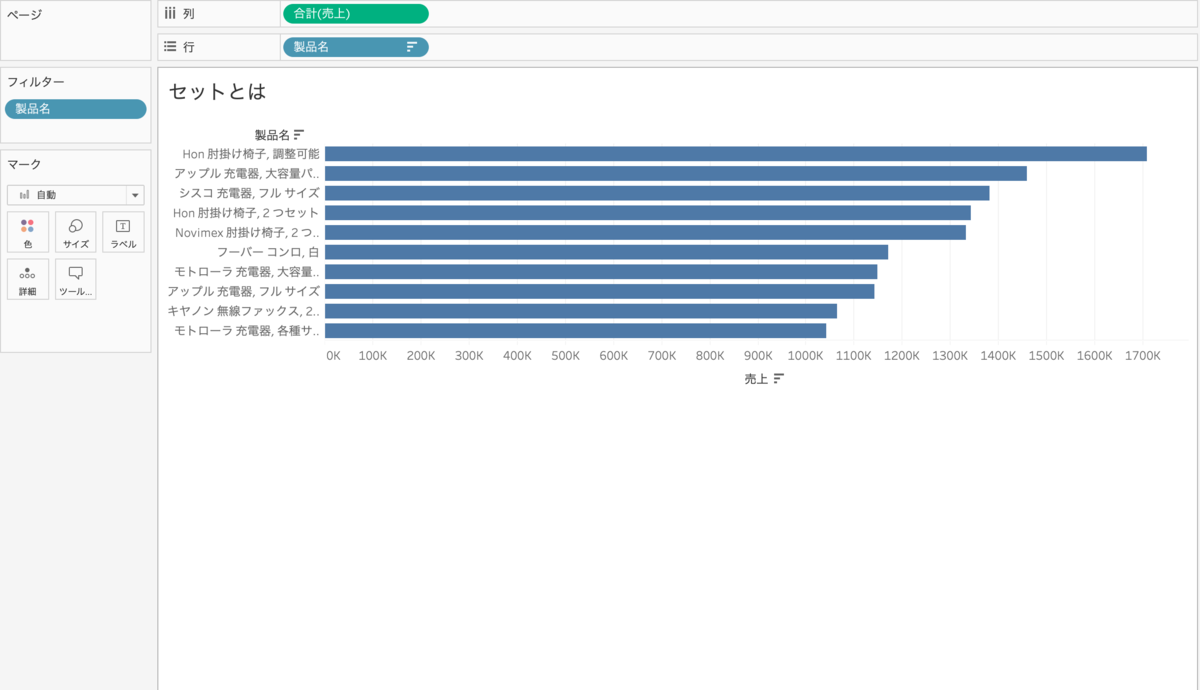
できました!ふんふん、セットなんて使わなくてもできました。
ここからセットを作っていきますね。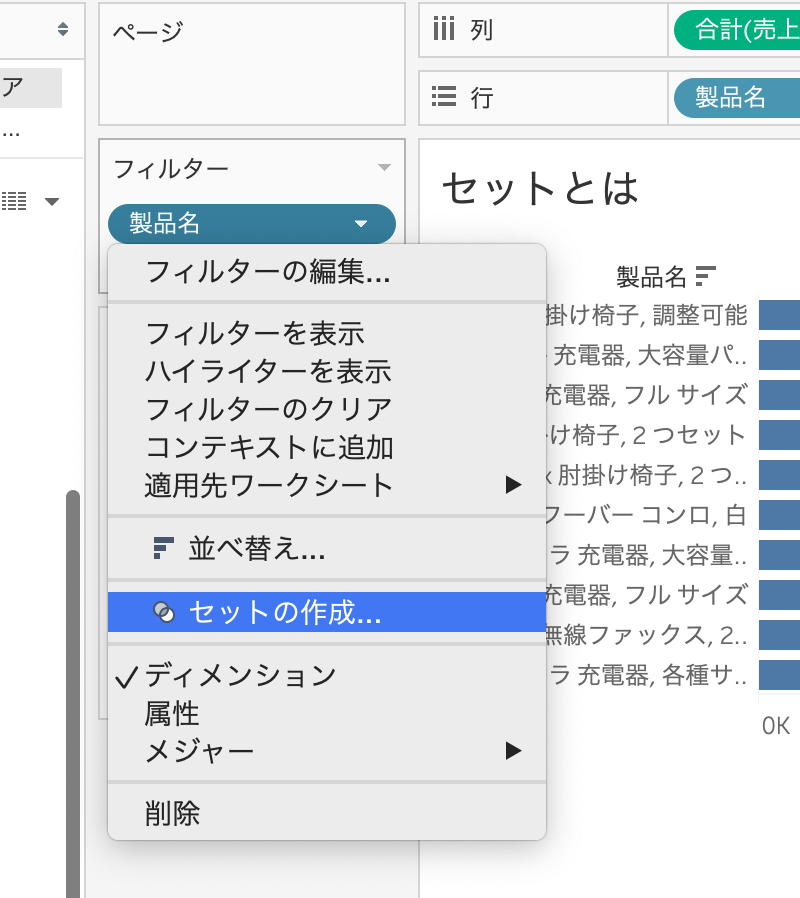
このフィルターをクリックして、「セットの作成」をクリックするとフィルターと同じ条件のセットを作ることができます。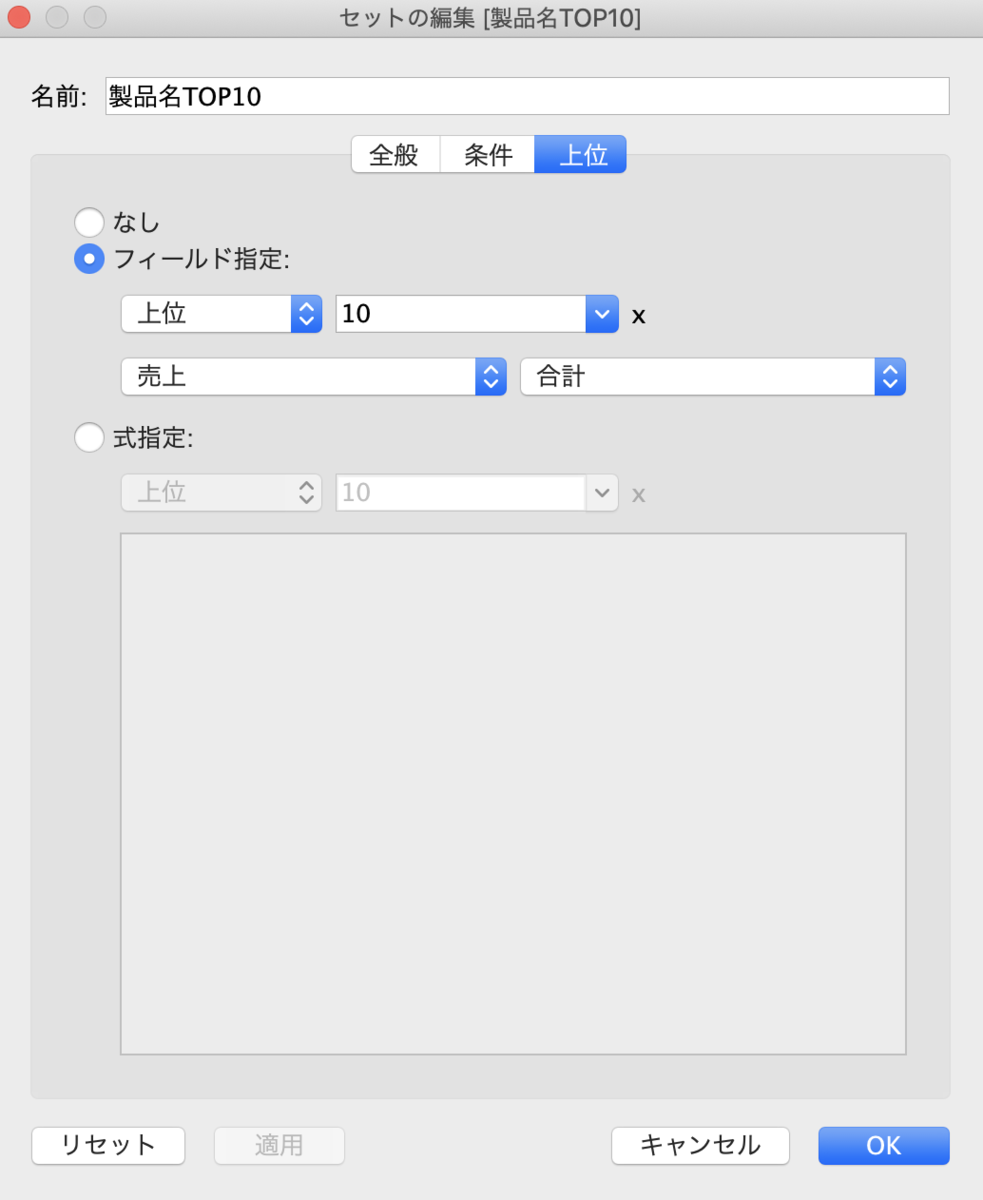
*地道に全部クリックしてもできます〜が、ここでは条件を指定できません。グループに似てますが(後述)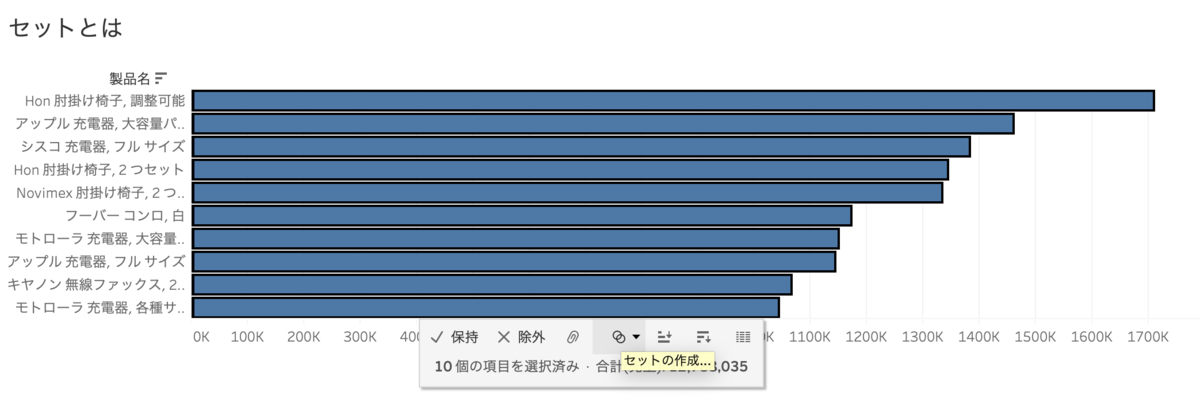
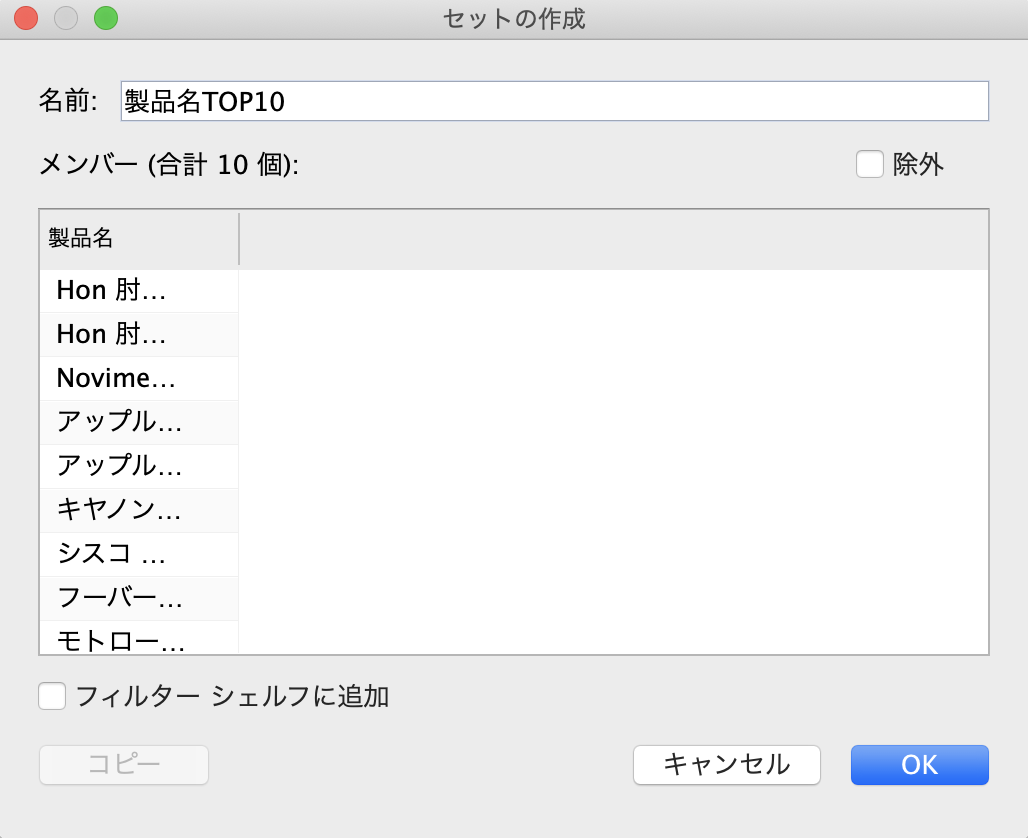
話を戻します!
作ったセットをフィルターに入れると、先ほどのフィルターを入れていた状態と同じになります。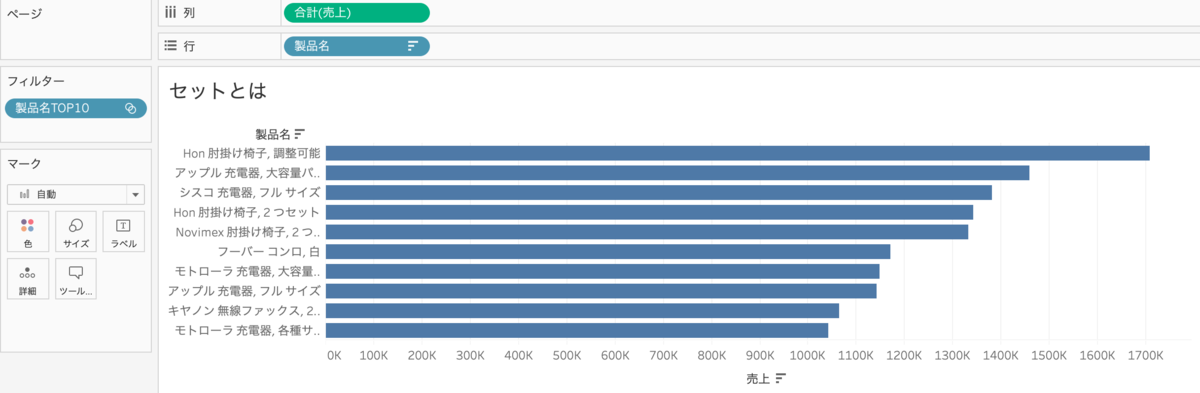
では行にセットを入れると、製品名を売上TOP10という条件でINとOUTに分けることができます。
セットの特徴として、OUTを見ることができるというのがあります。これはフィルターにはできませんね。
ここでは製品名売上TOP10のセットを作ることができました!
2.グループとは何が違うの!
これグループでもできるんじゃない!?
とも思った人いますよね!(私です)
では製品名売上TOP10グループを作ってみます。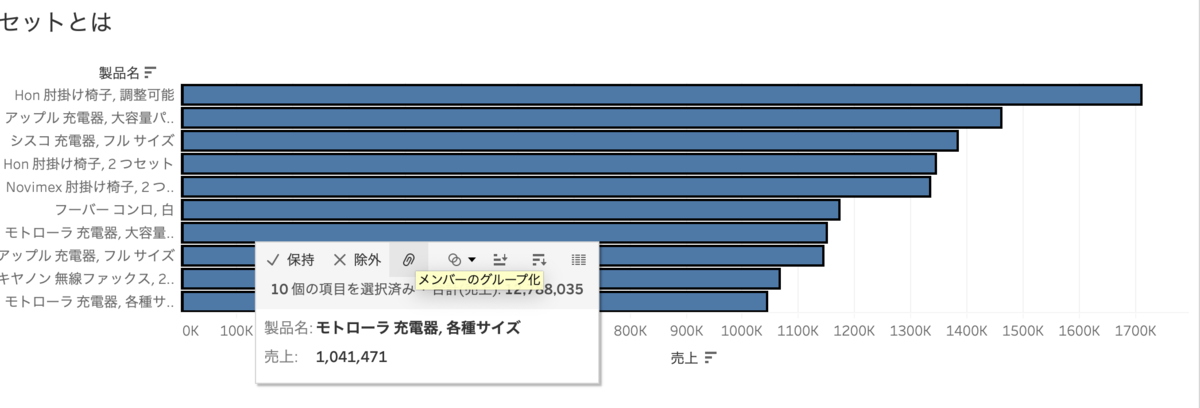
作ったグループをフィルターに入れると、先ほどのセットを入れていた状態と同じになります。
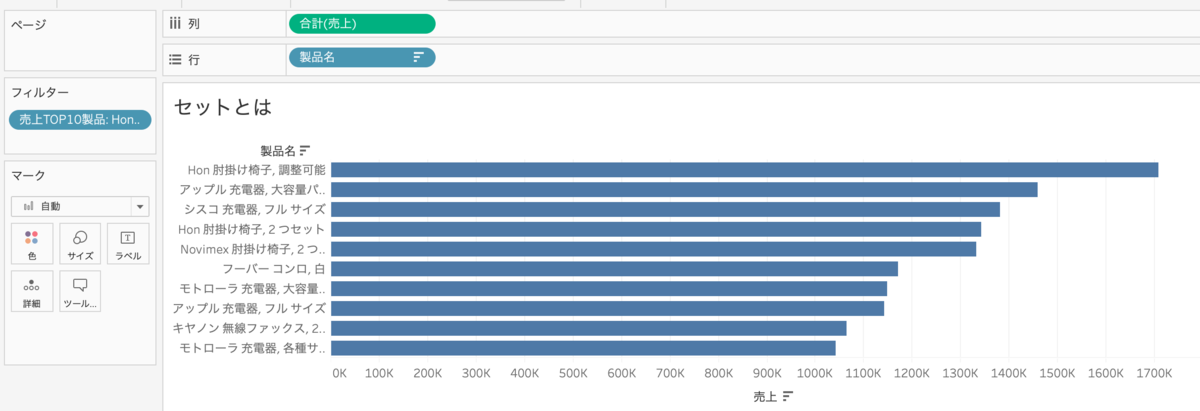
では行にセットを入れると、製品名を売上TOP10という条件でグループとその他(グループに以外)に分けることができます。

ますます一緒じゃーん!!
では、毎年製品名の売上TOP10をチェックしたい!
となったらどうでしょう。
"毎年"ということなので、年(オーダー日)をフィルター(単一値)に設定します。
下の画像では2013年の数字が出ていますが・・・
あれ、そもそも10個ないですね。売上TOP10の製品名を知りたいのに、10個ないですし
よくよく見ると、下のその他の売上はグループの売上を超えているものが多いです。
つまり、下の画像は2013年の製品名売上TOP10を出しているのではなく
売上TOP10(総合)の製品名の2013年での売上を出しているのです。
ちなみに10個ない理由は2013年に売上がない製品があるからです。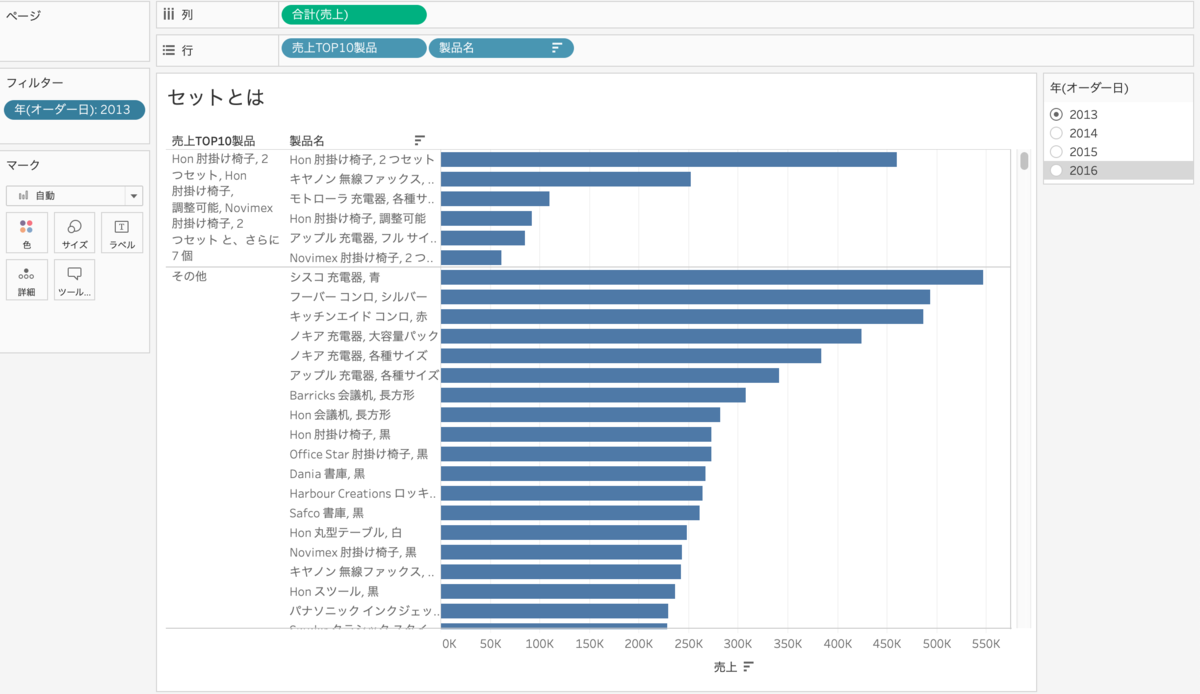
2014年に切り替えても、2015年に切り替えても製品名10個の中身は変わりません。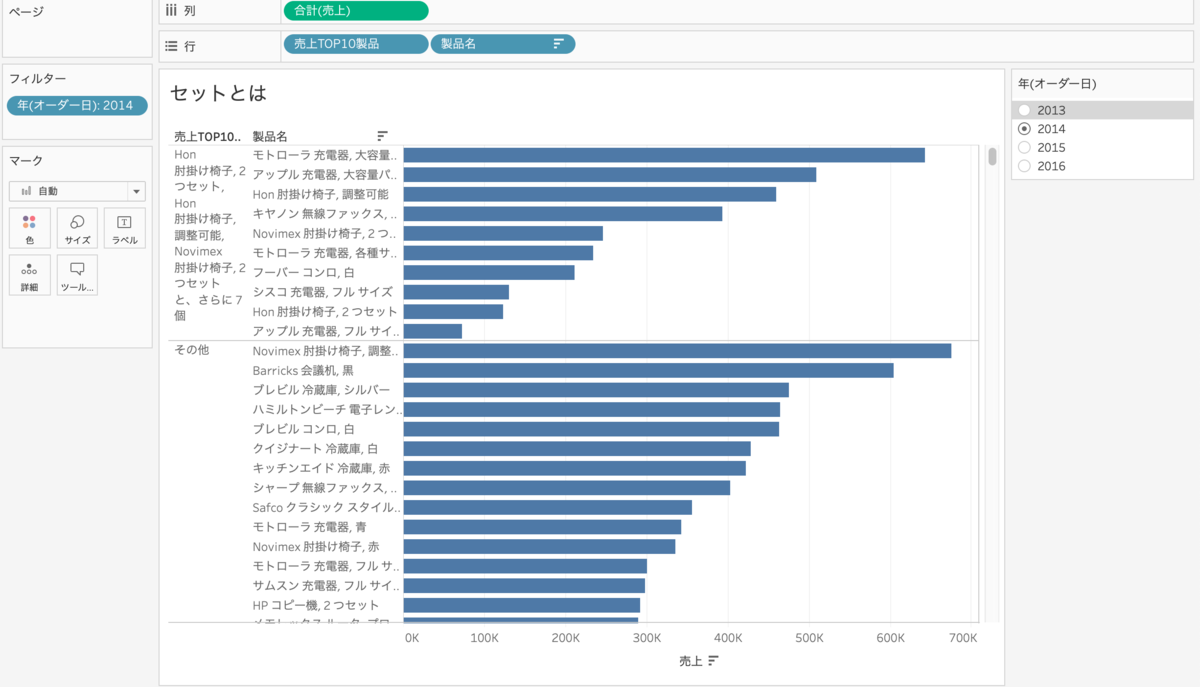
では、セットの方に年(オーダー日)を入れてみましょう。年(オーダー日)をフィルター(単一値)に設定します。
下の画像では、2013年の数字があります。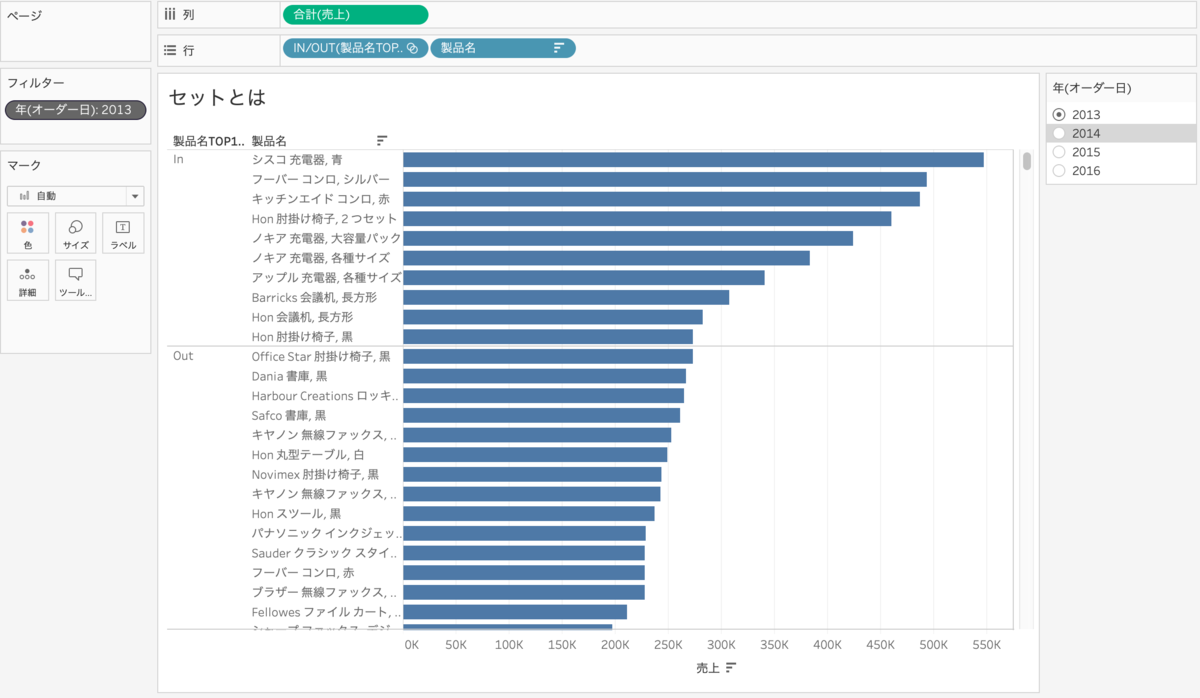
2014年や2015年に切り替えてみます。
2013年と同じ製品名ではないですよね
(2013年の売上TOP10製品名をグループにして色に入れています)
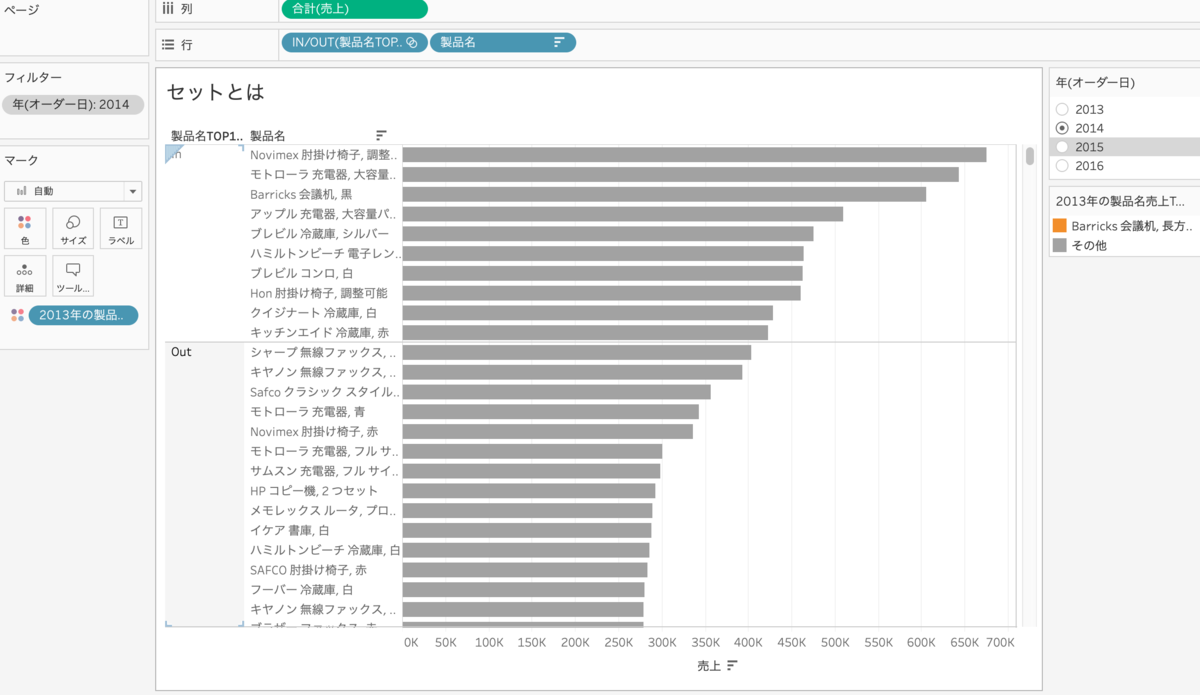
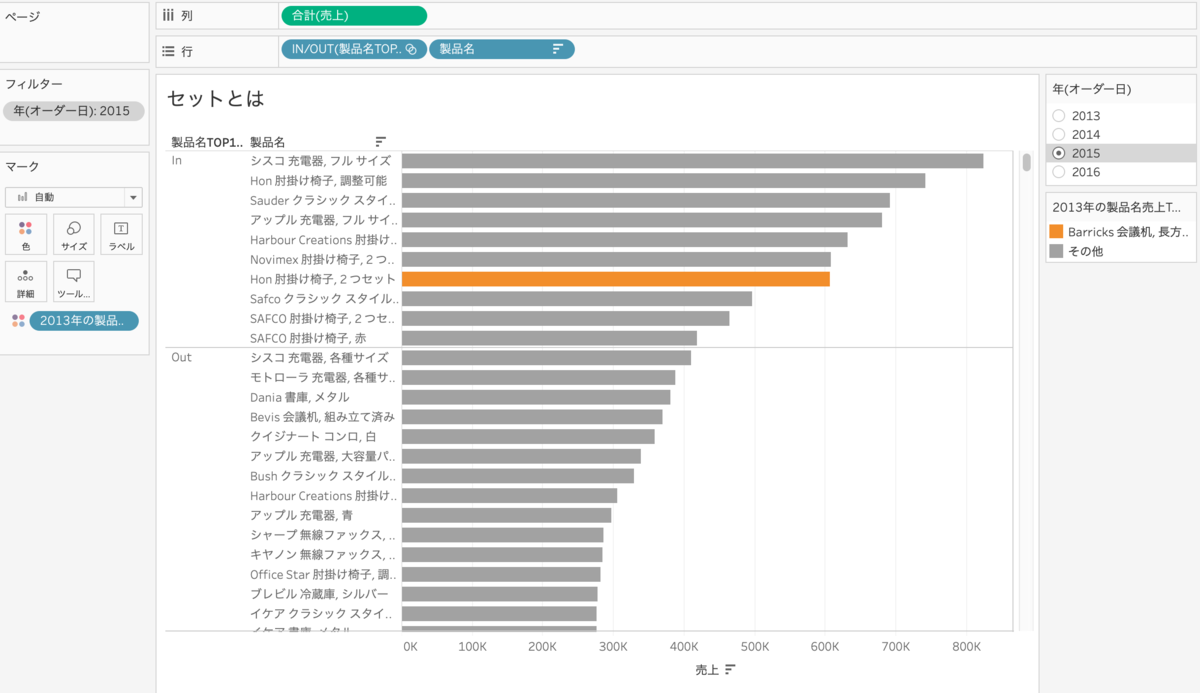
つまり、セットでは毎年の製品名売上TOP10を出しているのです。
最初の質問に返ってみると、「毎年製品名の売上TOP10をチェックしたい!」とのことなので、今回はセットの方が良さそうです。
2013年の売上TOP10製品を追いかけたい、というのであればグループの方が良いですよね。グループについてややこしくなったー!という方のためにグループ編どこかで書きます。
セットとグループは似ていますが、
セット→変動する
グループ→固定できる
と覚えると良いのではないでしょうか!
(おまけ)よく見る他のものを「その他」にまとめるのどうやるの?
これは、ずばり計算式です。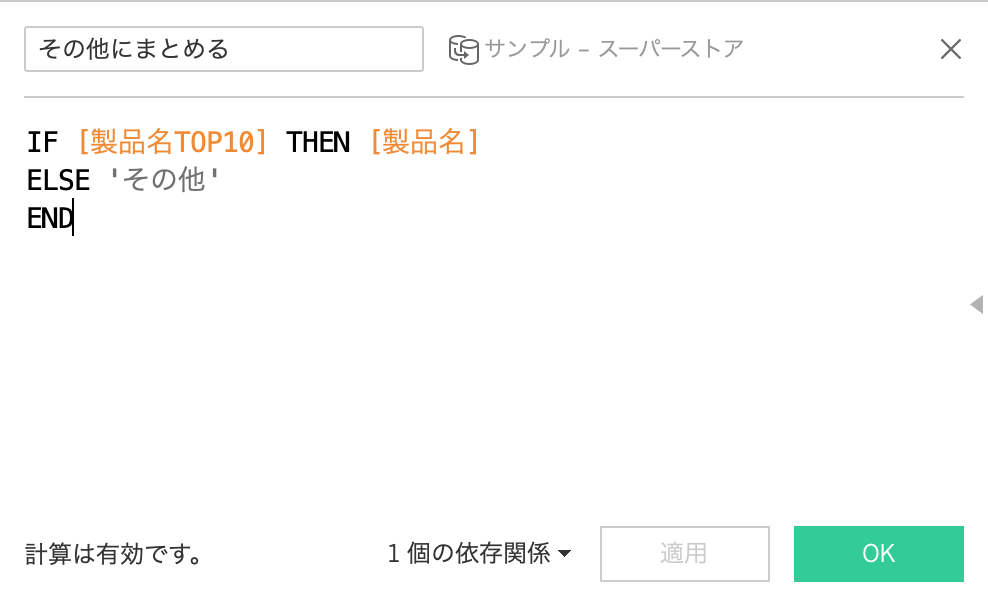
もし、製品名TOP10(セットのIN)だったら製品名を出してね。それ以外はその他にしてね。
という式を今入れている製品名の代わりに入れます。セット[製品名TOP10]を色に入れています。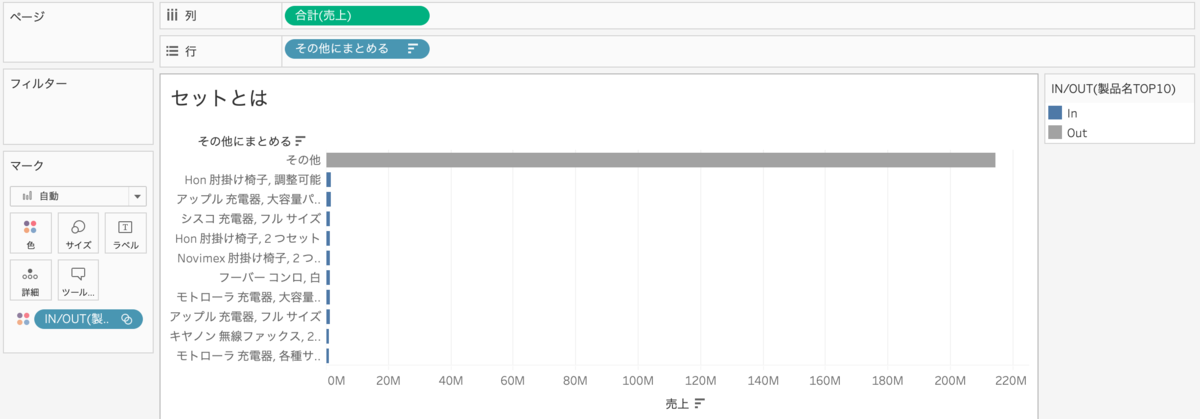
その他を下にしたければ、手動で移動させるか
セット[製品名TOP10]を行に入れて、IN/OUTに分ければ下に移動させることができます。
セットのヘッダーを非表示にすればOKです。線が気になるようでしたら、書式設定で調整しましょう。
3.結合セットとは!
突然ですが
製品名売上TOP10と製品名売上WORST10は同時に表示させることができますか?
フィルターでは複数の条件を入れることはできませんよね?
ここで結合セットの登場です。 (合体的なね)
(合体的なね)
結合したいセットを2つ選択します。
右クリックから「結合セットの選択」をします。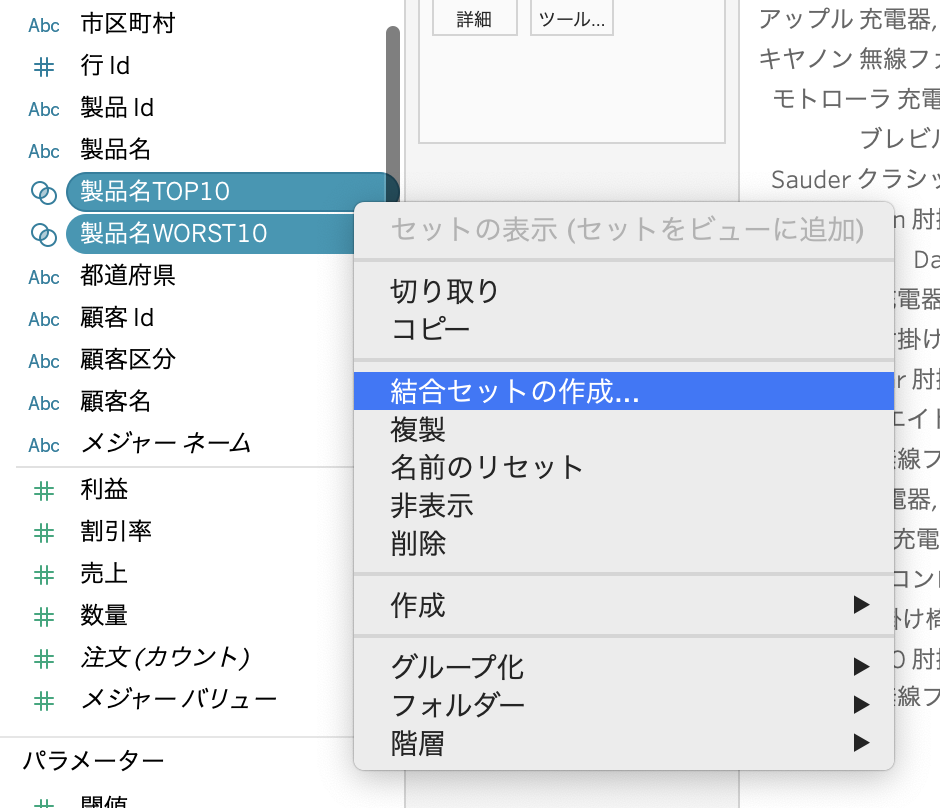
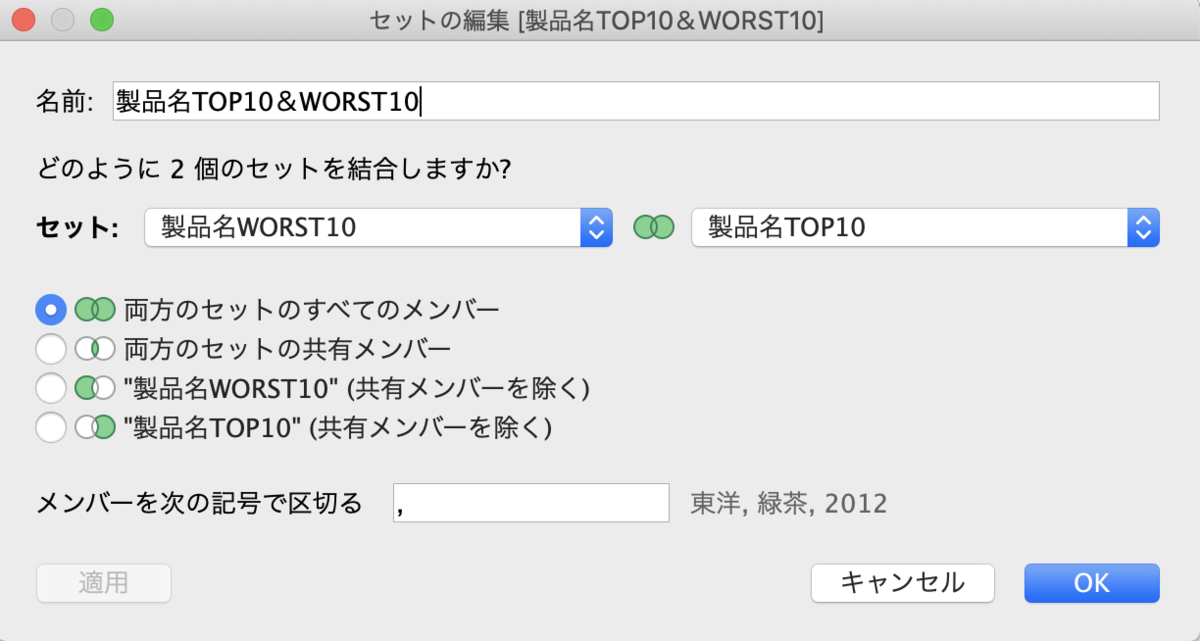
ここで、ベン図が出てきます。意味を考えながら慎重に選びましょう。 製品名WORST10と製品名TOP10製品名WORST10であり製品名TOP10の製品
製品名WORST10と製品名TOP10製品名WORST10であり製品名TOP10の製品 製品名WORST10だけど製品名TOP10じゃない製品
製品名WORST10だけど製品名TOP10じゃない製品 製品名WORST10じゃないけど製品名TOP10の製品
製品名WORST10じゃないけど製品名TOP10の製品
↑TOP10もWORST10も売上で作っているセットなので、この場合下3つは意味がないです
この結合セットをフィルターに入れると、製品名売上TOP10と製品名売上WORST10を同時に出すことができました!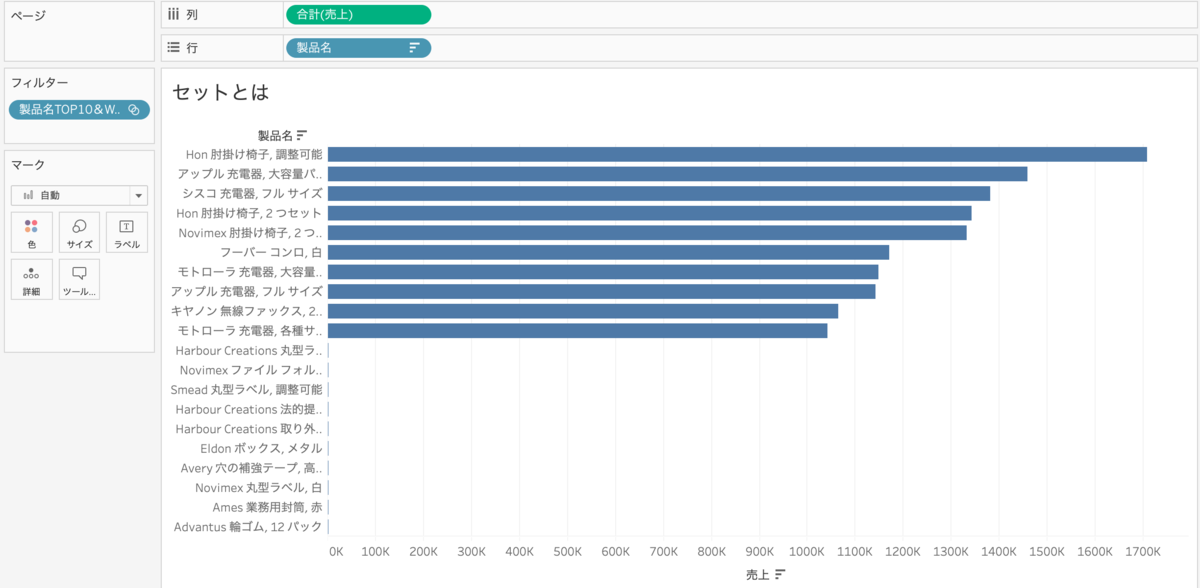
行に入れるとこんな感じです。
製品名売上TOP10と製品名売上WORST10がINになるというわけですね。
製品名売上TOP10と製品名売上WORST10を分けたいな〜という時はどうしましょうか。セット[製品名売上TOP10]を列と色に入れみましょう。
TOP10がINにWORST10がOUTになりました。セット[製品名売上WORST10]を入れれば逆になりますよね。
当たり前ですが、TOP10とWORST10では売上が全然違うのでOUTの方は潰れてしまいますので、行に入れて「軸の編集」から「独立した軸範囲」に設定すると良さそうですね。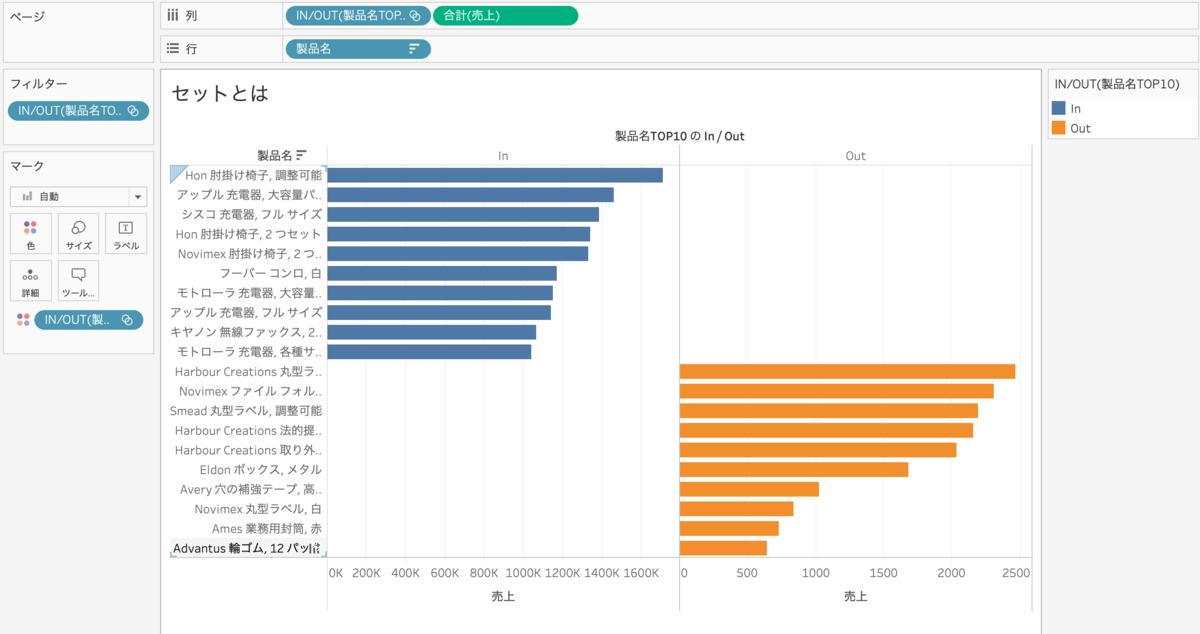
結合セット、いろいろ使えそうですね〜!
DATASaberのOrdにもたくさん出てくるので、いっぱい練習しましょう!
4.セットアクションとは
ごめんなさい!アクション編に飛ばします(まだ書いている途中ですが)
後ほどここにリンクを貼ります。思っていたよりセットの奥が深かった・・・(土下座)
5.まとめ
- セットとはディメンションから作られる、ある条件でIN/OUTの2つに分けるもの
- フィルターとは違って、OUT(それ以外の部分)を見ることができる
- セット→変動する グループ→固定できる
- 結合セットは複数の条件を保持できる(ベン図で調整する)
【Tableau】DATASaber:全Ord解説集~ありがとうDATASaberプログラム!~
はじめによんでください。
kaodora.hatenablog.com

- (Ord1)HandsOn-Fundamental
- (Ord2)Visual Best Practice l
- (Ord3)HandsOn-Intermediate l
- (Ord4)DATA Platform
- (Ord5)HandsOn-Intermediate ll
- (Ord6)Visual Best Plactice ll
- (Ord7)Peformance Best Plactice
- (Ord8)HandsOn-Advanced l
- (Ord9)HandsOn-Advanced ll
- ZEN問答は書きません!
- 終わりに
(Ord1)HandsOn-Fundamental
(Ord2)Visual Best Practice l
(Ord3)HandsOn-Intermediate l
(Ord4)DATA Platform
(Ord5)HandsOn-Intermediate ll
(Ord6)Visual Best Plactice ll
(Ord7)Peformance Best Plactice
(Ord8)HandsOn-Advanced l
(Ord9)HandsOn-Advanced ll
ZEN問答は書きません!
これに関しては答えを明記せずに書くことが難しいと思いました。
私自身ZEN問答は何度も落ちていて、同じコミュニティの方と2回ほどディスカッションをさせていただいて理解することができたので、ZEN問答はみなさんで意見を出し合うことが大切なのかなと思っております。
しかしながら、このZEN問答に取り組むにあたって前提条件がいくつか必要であると思いますので、もちろん私もお師匠に教えていただいたことですがここに残しておきたいと思います。
(ZEN問答前提条件)
・あなた(私)はDATASaberである。DATASaberになったあなたがするべきこと、してはいけないことを考える
・それは1000人気規模の大企業でも当てはまることか
・選択肢はどんなケースにも当てはまること
終わりに
このブログを始めたのはDATASaberの要件であったコミュニティポイント稼ぎのためでした。それから最終試験を受験して、結果を待っていた1週間にふと復習にOrd解説をしてみようと思ったのです。
社内でTableauユーザーが1人の私は、社内の人にTableauを伝えるというお仕事もあり操作の言語化は必須でした。このブログのおかげで、DATASaberの勉強をしていた時よりもTableauに向き合った気がします。
解説を書いている途中でDATASaberに合格することができて
Tableauを触って間もない時に、amazonでTableauに関する本を片っ端から買って、その中で「DATASaber」という言葉を知って、GoogleやTwitterで検索して、お師匠にお会いできてapprenticeになって・・・今では偉そうに解説なんてブログを書いていて、ずいぶん遠くまできたな〜と思いました。
統計知識もなくSQLもEXCELさえもまともに扱えなかった私が、DATASaberになるのにはとても苦労しました。同じコミュニティの方達と何度もディスカッションさせていただいて、一つ一つのOrdの理解に努めました。足を引っ張ったこともあるように思いますが、お仕事も年齢も全く違うみなさんとTableauを通してお会いできてDATASaberにチャレンジしてよかったなと何度も思いました。
お師匠にはディスカッション含め、何度もお時間を頂戴し質問に答えていただきました。今まで私が書いてきた解説はお師匠から教えていただいたことを文章にしているにすぎません。出来の悪い弟子をDATASaberにしてくださって本当に本当に感謝しています。こんなに素晴らしいお師匠なので師匠探しをしている方には全力でお勧めしたいです(勝手に)
このブログも「途中でやめようかな〜」と頭をよぎったこと3459762回ぐらいありますが、実は毎日20~50人くらいの方が読んでくださっていて、誰かのためになるのならと細々と続けることができました。こんな拙い文章を読んでTwitterで反応してくださった方々、嬉しくていつも感動していました。ありがとうございます。
春からデータ分析とは全く関係のないお仕事に就くため、Tableauともお別れです。
このブログも下書きのものを書き終えたらやめるつもりです。
しかしデータ分析やTableauの面白さを知ることができて本当によかったです。ストーリーテリングの素晴らしさを知ることができてデータの見方がガラリと変わりました。偏にDATASaberプログラムのおかげだと思っております。またこの世界に戻ってこれるよう頑張りたいと思います。
こんなに長く書くつもりがなかったのですが
本当の終わりに、Tableauを勉強する機会をくださった会社と、DATASaberという制度を作られたKTさんと、DATASaberプログラムを運営してくださった皆様、そしてお師匠に全力の感謝を申し上げます。
ありがとうございました!

【Tableau】DATASaber:HandsOn-Advanced ll(Ord9)解説
はじめによんでください。
kaodora.hatenablog.com

Q1
Ord9(1) pic.twitter.com/FXdqUJQIB1
— 動画掲載用 (@Kaodoramichan) 2021年1月18日
サブカテゴリごとの売上年推移を作成します。
サブカテゴリをフィルターに入れてテーブルに絞ります。
簡易表計算から前年比成長率(差の割合)の基準の値を2013年、または最初の値に設定します。
Q2
Ord9(2)-1,2 pic.twitter.com/eVlA7nlp2A
— 動画掲載用 (@Kaodoramichan) 2021年1月18日
都道府県の利益累計(簡易表計算)を出します。向きは表(横)です。
サブカテゴリをフィルターに入れて「椅子」のみにします。
利益の降順に並び替えます。
WINDOW_MAX(RUNNING_SUM(SUM([利益])))=RUNNING_SUM(SUM([利益]))
表内の利益累計最大値が利益累計と一致したら、真、それ以外は偽ね
という上の式を色に入れます。
すると最大値に色がつき、利益累計が最大になる都道府県とその利益の値を確認することができます。
Ord9(2)-3 pic.twitter.com/m68P3vRH5Y
— 動画掲載用 (@Kaodoramichan) 2021年1月18日
最大値の色を外します。
地域を色に入れます。すると棒グラフの形が変わってしまいました。
先ほどの利益の降順で都道府県は並んでいます。計算の向きは表(横)です。
ではこのグラフは何を表しているのでしょうか。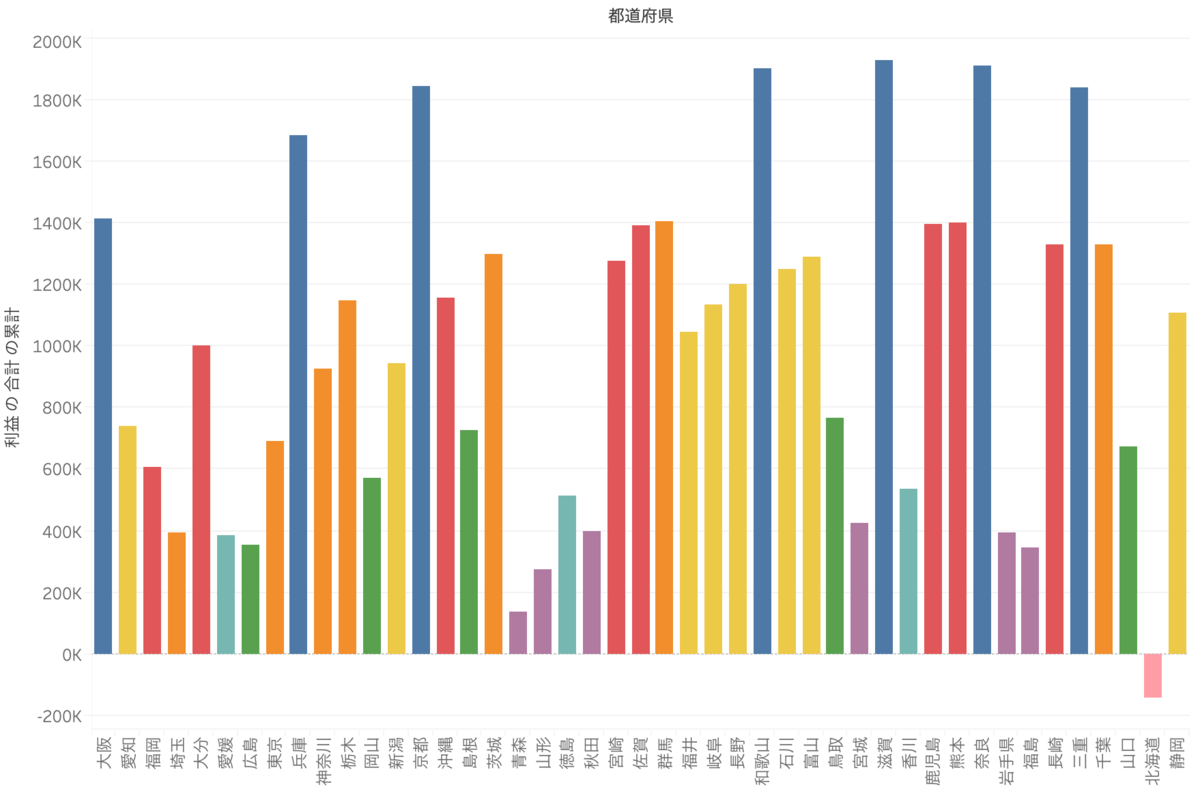
色に地域を足すということは、集計粒度をビューに足しているということですよね。
ここでは地域での集計が追加されて、地域ごとに累計がされているのです。
例えば、大阪の利益が次に累計されるのは、次に表に存在する兵庫県の時です。
つまりは関西地方の中だけで累計されていくのです。最終的な結果は三重県の数字になります。
この問題の場合、これでは困りますね。
全体の都道府県の累計の中で地域特性があるのかを見たいのでした。
そのために、地域を属性にします。
属性とは、その値に対して属性が1つであればその値が、複数であれば*が返されるというものでした。
大阪は関西地域という値しか持っていませんね(他の地域には属していない)
そのため、その値(大阪)が返されるというわけです。
(よくわかんないわっていう方は以下の記事を読んでくださいね)
kaodora.hatenablog.com
属性には区切らずに(集計せずに)、ラベルとして持っておきたい時に使うというものもありました。地域では区切りたくないけど、地域で色に分けたい!のでまさに属性を使う時です!!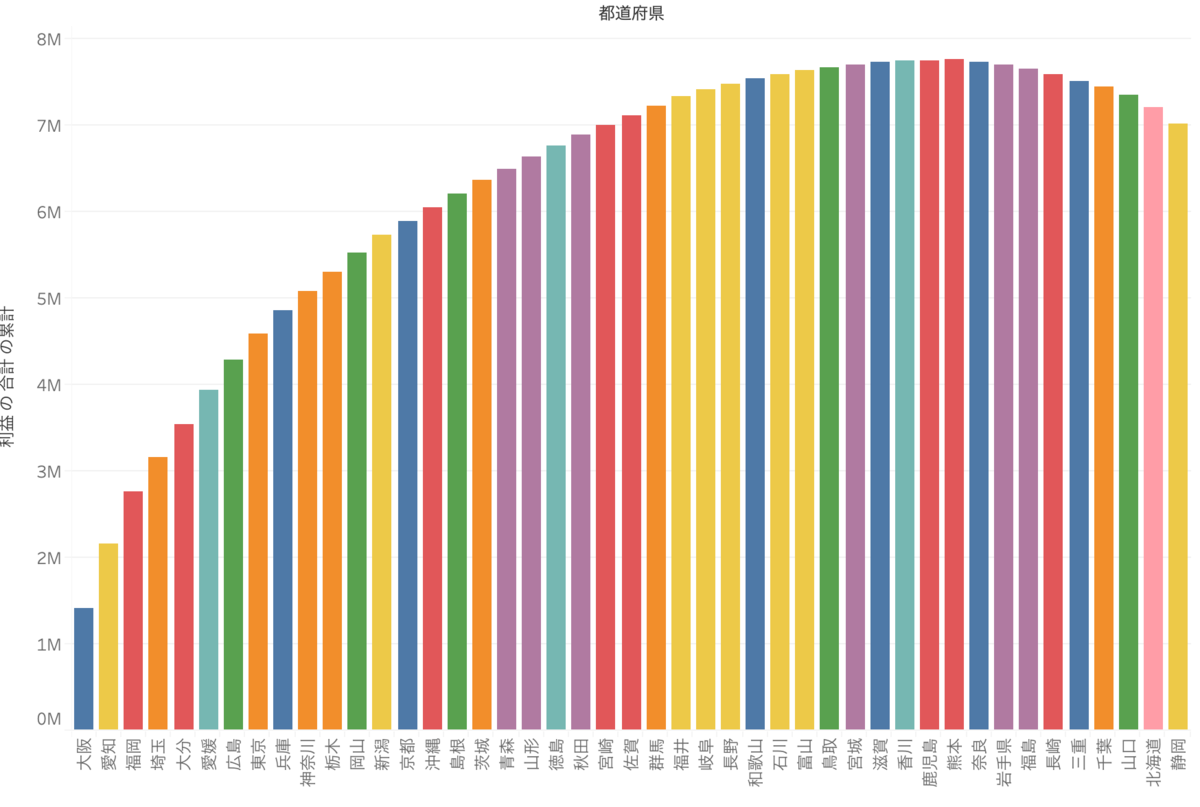
形が戻りました。地域特性がないことがわかります。
あとは、KTさんが動画で作られていたものえを作ります。
グラフチャートをガントチャートにして、合計(利益)をサイズに入れるとそれぞれの値の上に棒グラフが乗っかります。当たり前ですが、0に近づくにつれ小さくなりますね。下向きの方がいいな〜ということで、サイズの合計(利益)にマイナスをつけます。
すると、グラフが下向きになります。
最後に-合計(利益)の昇順に並び替えもします。
Q3
Ord9(3)-1,2 pic.twitter.com/egY7bDAfdF
— 動画掲載用 (@Kaodoramichan) 2021年1月18日
年四半期ごとの売上をサブカテゴリのランキングにします。(簡易表計算)
オーダー日、合計(売上)をそれぞれ不連続にします。
一つ一つを区切りたいためです。
kaodora.hatenablog.com
この時点でも回答を得られますが、見やすくするためにもう一工夫です。
チャートを棒グラフにします。こぼ棒グラフを広げるために
MIN(1)を列に入れます。
MIN関数は()内の最小値を返す関数です。つまり、MAX(1)でも代用可能。
MIN(1)の軸を固定にして、終了値を1にします。
(Tableauはグラフの先端が見えるように、軸は実際の値よりも大きい値が終了地になっています。)
サブカテゴリを色、とテキストに入れて回答を確認します。
Ord9(3)-3 pic.twitter.com/8jFZsft4wE
— 動画掲載用 (@Kaodoramichan) 2021年1月18日
色にカテゴリを入れます。
すると、カテゴリというディメンションで分けられてしまうので
カテゴリを属性にします。
すると、カテゴリで区切らずにラベルとして色で分けることができます。(Q2と同じ原理)
Q4
Ord9(4)-1 pic.twitter.com/VC1jN1P85A
— 動画掲載用 (@Kaodoramichan) 2021年1月18日
顧客(顧客名)ごとの利益を出します。
顧客名をフィルターに入れて、条件から上位10位を出し、利益TOP10顧客のセットを作成します。同様に利益WORST10顧客のセットも作成し、両者を選択して結合セットを作成します。
結合セットをフィルターに入れて、利益TOP10とWORST10の顧客のみビューに表示させます。
列に売上を入れます。
利益TOP10顧客セットを行に入れます。INはTOP10、OUTはWORST10の顧客と別名の編集から入れます。
Q4-1の回答を確認することができます。
Ord9(4)-2 pic.twitter.com/rSeyX3t75W
— 動画掲載用 (@Kaodoramichan) 2021年1月18日
先ほど列に入れた売上を、簡易表計算から差にして基準を最初の値(利益TOP1の顧客)にします。A4-2の回答を確認することができます。
Ord9(4)-3 pic.twitter.com/mNeiMjuIKe
— 動画掲載用 (@Kaodoramichan) 2021年1月18日
利益のランクを作成します。
簡易表計算からペイン(下)のランクにして、並び順を昇順にします。
降順だと利益の多さ順に並ぶことになりますが、問題にはWORST何位か(下から何番目か)を聞かれているためです。Q4-3の回答を確認することができます。
Q5
Ord9(5) pic.twitter.com/Ga48NZEvk6
— 動画掲載用 (@Kaodoramichan) 2021年1月18日
年四半期の売上推移を棒グラフで出します。
簡易表計算から表(横)の累計・最大値にします。すると最大値を更新した時にその値を返してくれます。
この表計算のかかった売上を行に複製して片方のチャーと円にし、二重軸にします。軸の同期は忘れずにしましょう。
INDEX()>1 AND RUNNING_MAX(RUNNING_MAX(SUM([売上])))=SUM([売上])
行数が1以上で(つまりは最初の値以外)で
表内の売上合計の累積最大値が売上合計と一致したら真、あとは偽ねという式です。
上の式を色に入れると、最大値を更新した時のみに色をつけることができます。
Q6
Ord9(6) pic.twitter.com/XpWPOC3UpG
— 動画掲載用 (@Kaodoramichan) 2021年1月18日
まずは利益率を作成します。もうお馴染みですね。
SUM([利益])/SUM([売上])
改めて確認したいからはこちらをどうぞ!
kaodora.hatenablog.com
そして、データ内の利益率をLOD計算で出します。
{SUM([利益])/SUM([売上])}
これも曖昧な方はこちらをどうぞ!
kaodora.hatenablog.com
利益率と利益率(全体)を複合グラフにします。
メジャーネームを列から取ると、グラフが積み上がりました。
メジャーネームを色とサイズに入れます。
そこでツールバーの分析からスタックマークをオフにすると、2つのグラフを積み上がらずに0から並びます。
テキストを表示させて、書式設定からパーセンテージにします。
違うシートにサブカテゴリごとの利益率を降順に並べます。
ダッシュボードで両シートを並べて、フィルターを除外にし、下位3位のサブカテゴリを選択すると回答を確認することができます。(Ord3Q1でやりましたね)
Q7
Ord9(7) pic.twitter.com/BZG0a3CJfr
— 動画掲載用 (@Kaodoramichan) 2021年1月18日
列にオーダー日(年) を入れて、売上と売上前年比成長率でサブカテゴリの散布図を作成します。
売上前年比成長率を色に入れます。
年を切り替えて表示できるようにしたいのですが、フィルターに入れるとオーダー日による表計算のため前年比成長率が表示されなくなります。
LOOKUP(MIN(DATEPART('year', [オーダー日])),0)
LOOKUP関数を使います。0行前のオーダー年最小値を返してね。
つまり、その年を数字で返してねというような感じです。
これをフィルターに入れると、前年比成長率を失わずにそれぞれの年を切り替えることができます。
2013年はいらないのですが、2013年を除外にしてしまうと2014年の前年比成長率が表示されなくなるので、2013年は非表示にします。
作ったシートをダッシュボードに入れて、画面のサイズをスマートフォンにします。
散布図は正方形になるようにしましょう。
Q8
Ord9(8) pic.twitter.com/PqVWpCJlGv
— 動画掲載用 (@Kaodoramichan) 2021年1月18日
出荷までにかかる日数をお馴染みのDATEDIFF関数で出します。
DATEDIFF('day',[オーダー日],[出荷日])
オーダー日と出荷日の差を日で出してね。
週ごとの出荷までにかかる平均日数を出します。
行の出荷までにかかる平均日数を複製し片方のチャートを円にして二重軸にします。
軸の同期をします。
アナリティクスペインから-3,3の標準偏差を入れます。
AVG([出荷までにかかる日数])>
WINDOW_AVG(AVG([出荷までにかかる日数]))+WINDOW_STDEV(AVG([出荷までにかかる日数]))*3
[出荷までにかかる日数]平均が
表内の[出荷までにかかる日数]平均の平均に、[出荷までにかかる日数]平均の標準偏差3を足したものより大きければ真、それ以外は偽ね。というややこしやな式ですが、
つまりは標準偏差3を超えたら真、それ以外は偽というわけです。
上の式を色に入れます。もう回答がわかりますね!
Ord9(8)-2 pic.twitter.com/vgrDyL8aHr
— 動画掲載用 (@Kaodoramichan) 2021年1月18日
違うシートに市区町村ごとの出荷までにかかる平均日数を出します。
地域特性を見たいので、列と色に地域を追加します。
ダッシュボードにQ8-1で作成したシートとこのシートを並べます。
フィルターをかけて、標準偏差を超えた週を選択して原因となる市区町村、地域を確認します。
Q9
Ord9(9) pic.twitter.com/58jdQvosdN
— 動画掲載用 (@Kaodoramichan) 2021年1月19日
メーカー情報をブレンディングします。
オーダー日(年)をフィルターに入れて2016年に絞り、四半期ごとのメーカー売上推移を出します。
メーカーをフィルターに入れて、ワイルドカードで「s」の後方一致を設定します。
するとメーカー名が「s」で終わるメーカーに絞ることができます。
それぞれのトレンドを見たいので、軸の編集から独立した軸範囲にします。
最後の値を強調するためにこのような式を作ります。
IF LAST()=0 THEN SUM([売上]) END
もし、後ろから一つ目だったら売上合計を出してね。
これを列に追加して、合計([売上])と二重軸にします。
軸の同期をすると折れ線グラフと円がぴったり重なります。円の大きさを少し大きくして、最後の値のみテキストを表示させます。それでは回答を確認しましょう。
Q10
Ord9(10) pic.twitter.com/krMscA1rlU
— 動画掲載用 (@Kaodoramichan) 2021年1月19日
四半期ごとの売上を地域ごとの出して、これをランクチャートにします。
簡易表計算から地域のランクにします。
軸の編集から軸を反転させます。列の合計([売上])を複製して片方を円にします。
これらを二重軸にします。複製した方の軸も反転させましょう。軸の同期も忘れずにします。
地域を円の色に入れて、ランクを円のテキストに入れます。
地域を線のテキストに入れます。
最後に間のオーダー日を選択して除外すれば、売上開始当初(2013/1Q)と最終四半期(2016/4Q)でランキングの変動を見ることができます。
Q11
Ord9(11)ー1 pic.twitter.com/4sSigvQrjd
— 動画掲載用 (@Kaodoramichan) 2021年1月19日
カテゴリをフィルターに入れて、家電に絞ります。
週ごとの売上推移を棒グラフで出します。
基準となる値(今回は問題にあるように500,000)を超えたら色をつけるようにしたいのですが、可変にする必要があるためパラメーターを使います。
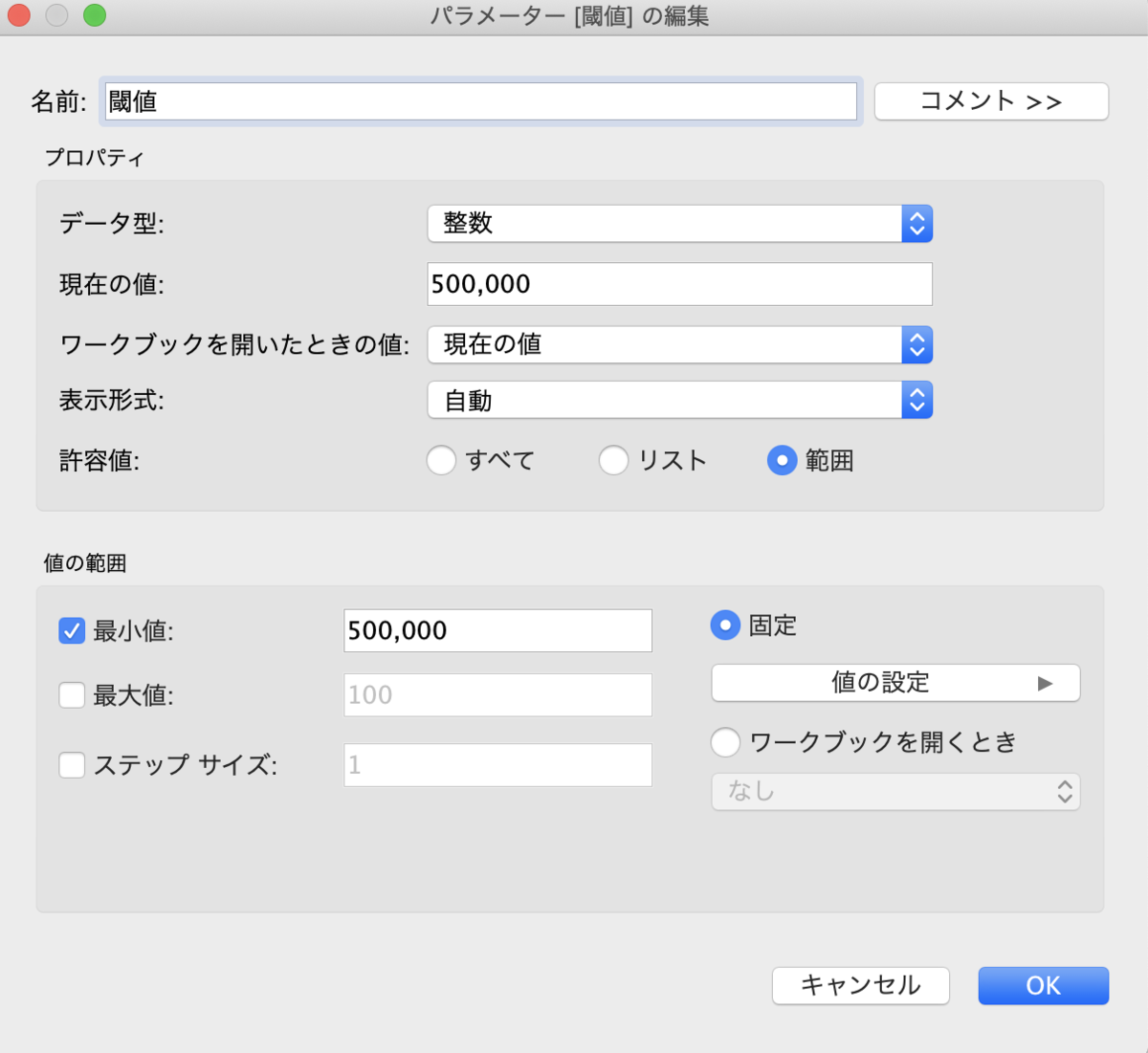
「閾値」という名前にします。そして、
SUM([売上])>=[閾値]
売上合計が閾値(今の値は500,000)を超えていたら真、それ以外は偽ね
という式を色に入れます。売上合計が500,000を超えた週に色がつきました。
IF [閾値判定] THEN PREVIOUS_VALUE(0)+1 ELSE 0 END
もし売上合計が閾値(今の値は500,000)を超えていたら、前の行の計算(つまり0)に1を足して返してね、という式です。
PREVIOUS_VALUE計算は最初の行は普通に計算されます。つまり最初の値は0になります。
上の式をテキストに入れると、閾値(500,000)を超える週数を数えることができます。
テキストの表示を最大値のみにすると、回答を得ることができます。
Ord9(11)ー2 pic.twitter.com/yXlTI3gMds
— 動画掲載用 (@Kaodoramichan) 2021年1月19日
IF [閾値判定] THEN PREVIOUS_VALUE(0)+(SUM([売上])-[閾値])
ELSE 0 END
もし売上合計が閾値(今の値は500,000)を超えていたら、前の行の計算に合計売上から閾値(500,000)を引いた数字を足してね。
PREVIOUS_VALUE計算は最初の行は普通に計算されます。つまり最初の値は、売上から閾値(500,000)を引いた値が返されます。
上の式をテキストに入れると回答を確認することができます。
【Tableau】LOD計算とは?〜EXCLUDE編〜

LOD計算~EXCLUDE計算編~です💡💡💡
ここまできました!😭
LOD計算の概要はこちらです。
kaodora.hatenablog.com
EXCLUDE計算の特徴
1.EXCLUDE計算はビュー内のディメンションを無視します。
{EXCLUDE[サブカテゴリ]:SUM([売上])}
この式はサブカテゴリを無視して、ビュー内のディメンションで集計して売上合計を返します。
ただし、無視したいディメンション(サブカテゴリ)は必ずビュー上に存在していなければいけません。
しかしLOD計算は非集計として扱われるため
ATTR({EXCLUDE[カテゴリ]:SUM([売上]})実際ビュー上では集計関数のついたこのような式になります(デフォルトは属性)
EXCLUDE計算は
「○○(ディメンション)を無視したビュー内のディメンショごとの集計関数□□」を出すと覚えましょう。
よってこの式は上の画像に倣い、サブカテゴリを無視したカテゴリごとの売上合計、となります。
2.どんな集計関数でも結果は変わりません
上の説明で、さらっと集計関数をATTRにしてしまいました!
ATTRとは属性のことですがその結果が1つだったらその値を返し、複数であれば*(アスタリスク)を返すというものでした。よく非集計を集計にする際に使いますね。
kaodora.hatenablog.com
EXCLUDE計算が他のLOD計算と違うとことは、ここです。
どんな集計関数を使っても結果は変わりません。
中間テーブルで集計した計算をさらに集計する、ということができないからです。
デフォルトは属性になりますが、どの集計関数でも大丈夫です。
3.EXCLUDE計算の活用例
EXCLUDE計算を使うときはどんな時でしょうか!
一例をご紹介します。
○全体に対する割合を出したい時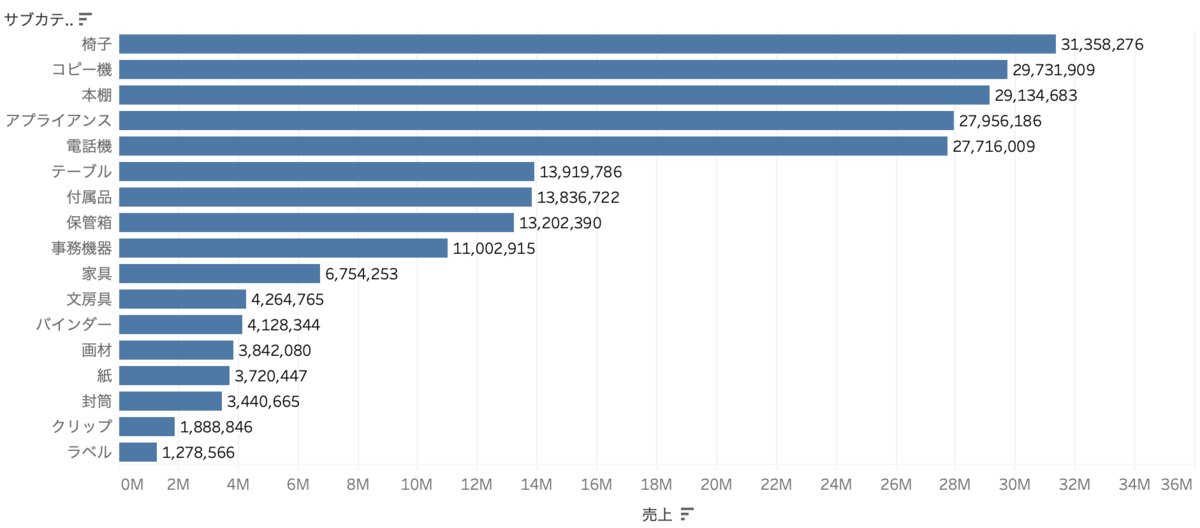
上の画像ではサブカテゴリごとの売上を出していますが、数字の横に全体の割合(%)を出したい場合はどうしましょう。それは以下の式で出すことができます。
SUM([売上])/SUM({EXCLUDE[サブカテゴリ]:SUM([売上])})
サブカテゴリの集計を無視した売上は、全体の割合ですよね。
この式をテキストに追加すると、、出すことができました!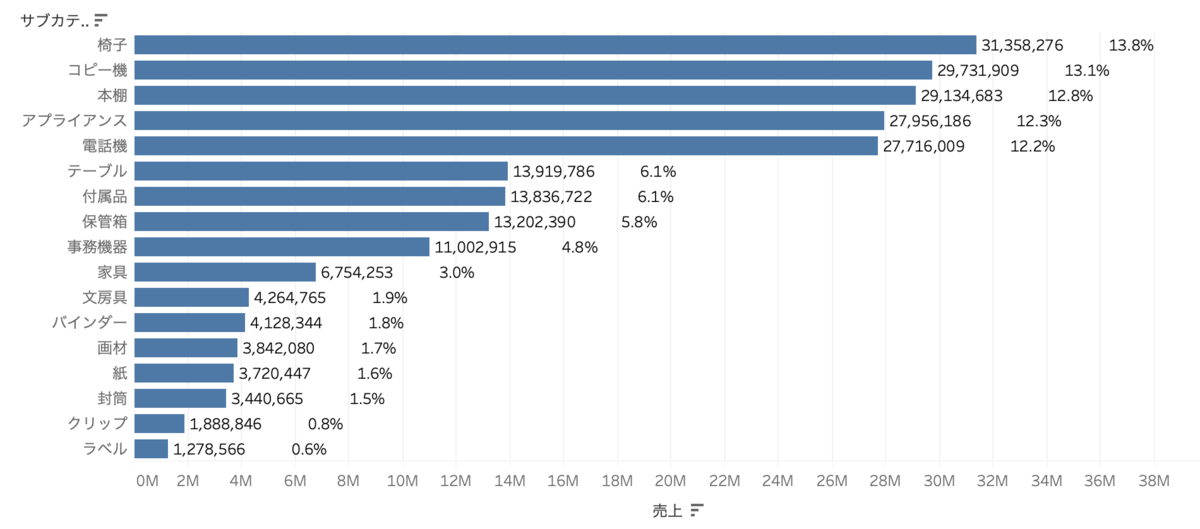
4.EXCLUDE計算とフィルターの関係

EXCLUDE計算はディメンションフィルターがかかった後に計算されます。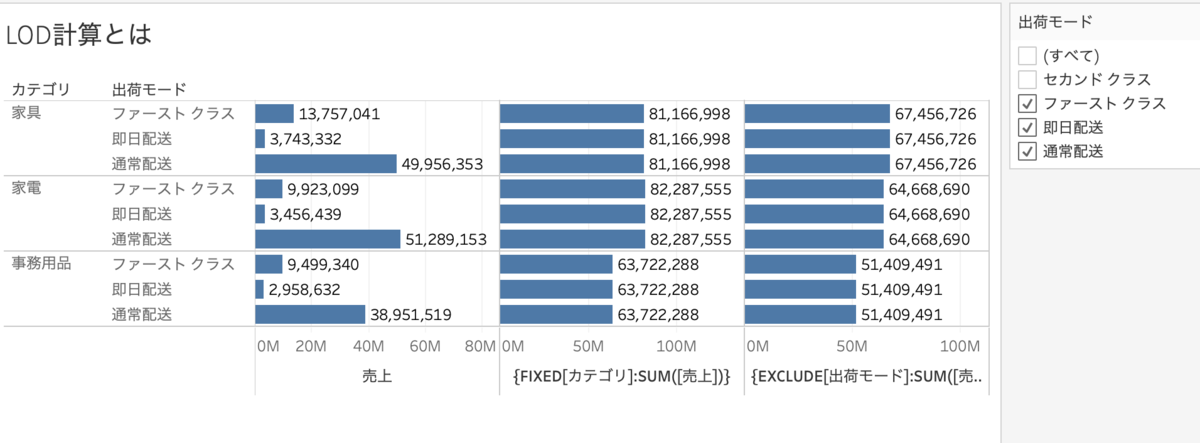
上の写真のように、
{FIXED[カテゴリ]:SUM([売上])}
{EXCLUDE[出荷モード]:SUM([売上])}をそれぞれビューに入れます。(どちらもカテゴリごとの合計売上)ですが
以下のように出荷モードでフィルター(ディメンションフィルター)をかけるとEXCLUDE計算だけ数字が変わることがわかります。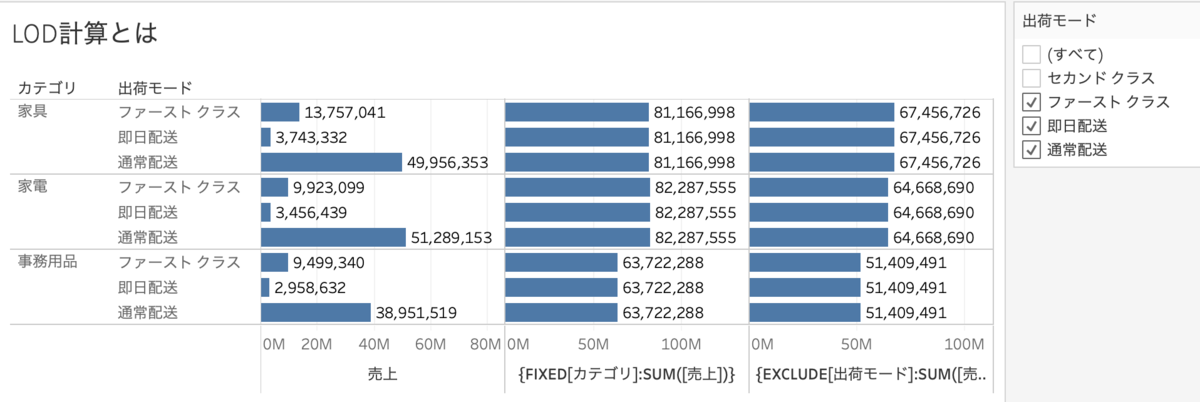
これは裏側で以下のようなことが起こっています。

繰り返しになりますが、ディメンションフィルターの後にEXCLUDE計算は集計されます。
EXCLUDE計算の例
EXCLUDE計算は先ほどにもありましたように、
「○○(ディメンション)を無視したビュー内のディメンショごとの集計関数□□」でした。
下の例を見て、口に出してガンガン練習しましょう。
・SUM{EXCLUDE[カテゴリ]:AVG(利益)}
→カテゴリを無視したビュー内のディメンションごとの平均利益
・SUM{EXCLUDE[カテゴリ]:COUNTD([顧客id])}
→カテゴリを無視したビュー内のディメンションごとの顧客idの個別のカウント
・{EXCLUDE[顧客id]:MAX([オーダー日])}
→顧客idを無視したビュー内のディメンションごとの最終オーダー日
(集計関数以下が「日付型」のため、このFIXED計算も「日付型」になります。よって、非集計として、式の前に集計関数がつくことはありません。)
【Tableau】LOD計算とは?〜INCLUDE計算編〜
{INCLUDE[都道府県]:SUM(売上)} SUM({INCLUDE[都道府県]:SUM([売上]})とは先ほど、市区町村を考慮した都道府県ごとの合計売上の合計と言いました。 しかし、ディメンショの数が多い時など入れ忘れを防ぐためにもINCLUDE計算を活用した方が良さそうですね! AVG(売上)はSUM(売上)を、その行数で割っているのでした。(安城だったら、安城のSUM(売上)を安城の行数で割っている) 余談ですが、{INCLUDE[都道府県]:AVG(売上)}にすれば、AVG(売上)と数字は一致します。裏の中間テーブルがどんな粒度で集計されているのか、を意識すればいいと思います! INCLUDE計算は先ほどにもありましたように、 ・SUM{INCLUDE[カテゴリ]:AVG(利益)} 次回EXCLUDE編です💡💡💡 
LOD~INCLUDE計算編~です🧊🧊🧊
個人的には1番難しかったINCLUDE計算ですが、言葉にして見れば意外と簡単かもしれません。
LOD計算の概要はこちらです。
kaodora.hatenablog.com
INCLUDE計算の特徴
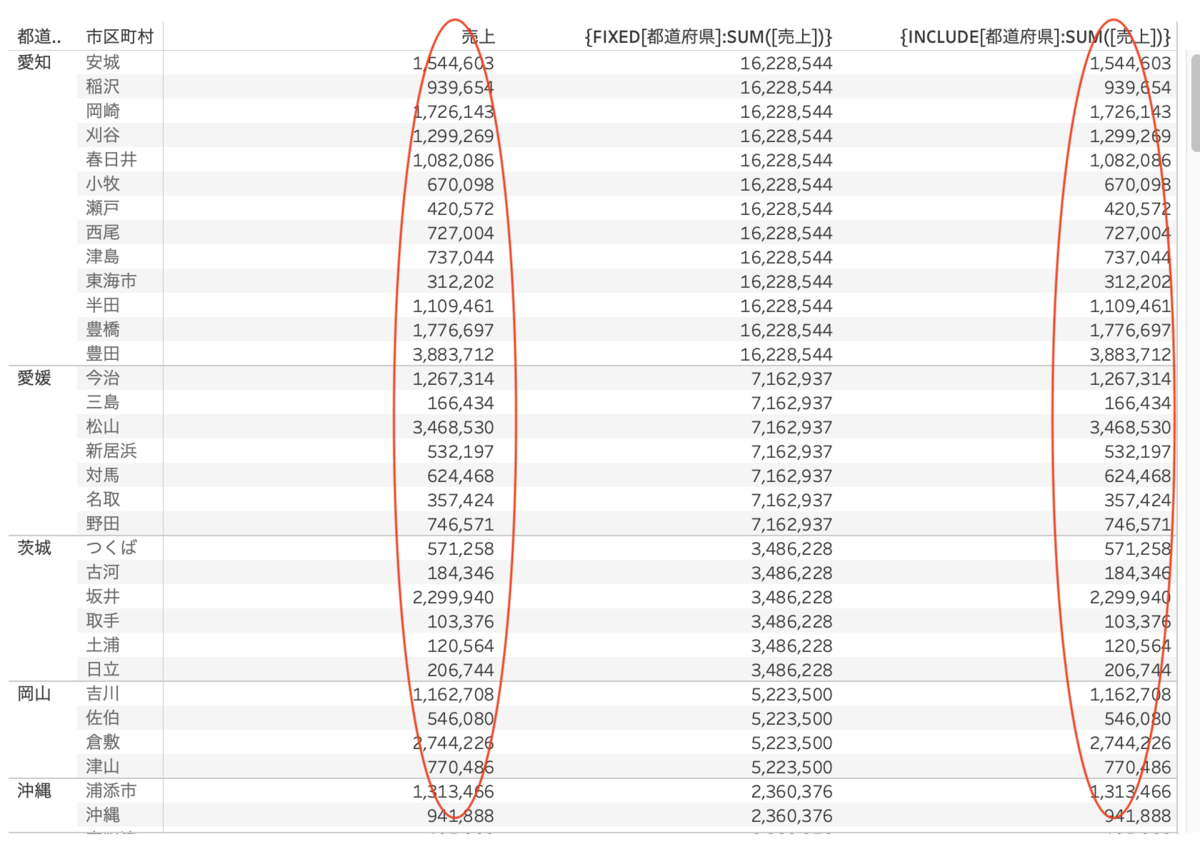
1.INCLUDE計算はビュー内のディメンションを考慮します。
この計算はビュー内のディメンションを考慮した都道府県ごとの売上合計です。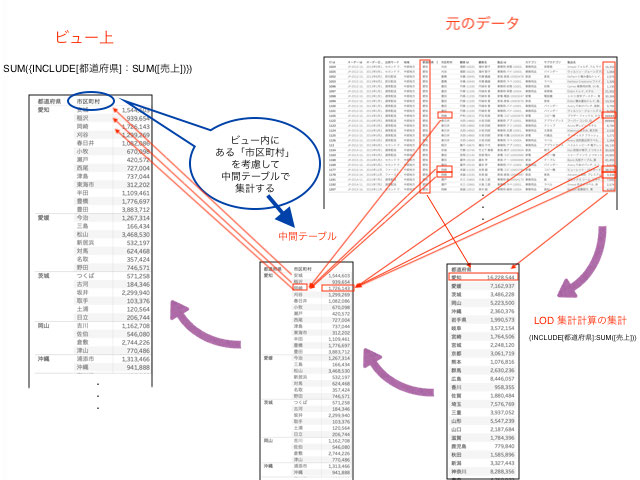
しかしLOD計算は非集計として扱われるため
SUM({INCLUDE[都道府県]:SUM([売上]})実際ビュー上では集計関数のついたこのような式になります(デフォルトは合計)
INCLUDE計算は
「ビュー内のディメンションを考慮した○○(ディメンション)ごとの集計関数□□の△△(集計関数)」を出すと覚えましょう。
よってこの式は上の画像に倣い、市区町村を考慮した都道府県ごとの合計売上の合計、ということになります。2.FIXED計算との違い

SUM({FIXED[都道府県]:SUM([売上]})と
SUM({INCLUDE[都道府県]:SUM([売上]})を比べてみます。
FIXED編にもあったように、FIXED計算は宣言したディメンション以外のものを無視し、ビューに対して独立しています。
上の画像を見るように、市区町村では集計せず、同じ数字(都道府県ごとの売上合計の合計)が並んでいます。
一方で、INCLUDE計算は市区町村を考慮した(市区町村で集計した)結果が返されています。3.FIXED計算と置き換えできます。

では、SUM({FIXED[都道府県],[市区町村]:SUM([売上])})はどうでしょうか。
FIXED計算のお約束に則ると、都道府県、市区町村ごとの合計売上の合計ですね。
これは、今回のINCLUDE計算と同じ意味になります。
つまりは、INCLUDE計算はFIXED計算の宣言するディメンションを複数に増やすことで置き換えることが可能です。4.通常の集計とINCLUDE計算の違い
あれ、通常の集計(SUM(売上))とINCLUDE計算同じじゃない?INCLUDEにする必要あんの?
と思った方いますか。あ、私です。
これは両者を平均すると簡単です。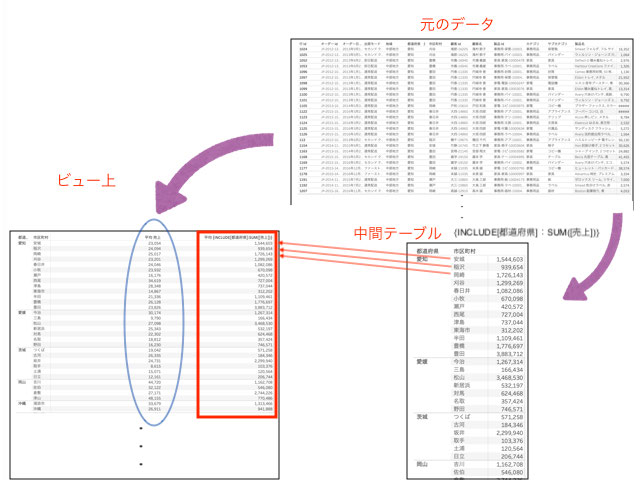
つまり、粒度はこのデータ自体の「1購入ごとの」でした。
しかし、INCLUDE計算は一度中間テーブルで市区町村を考慮して、都道府県ごとの合計売上を出しているのでした。つまり、粒度は「都道府県、市区町村ごとの」です。
都道府県、市区町村ごとの合計売上をさらに平均にしても数字は同じですよね。
結論、通常の集計とINCLUDE計算は粒度が全く異なるので違います!5.INCLUDE計算とフィルターの関係
INCLUDE計算はディメンションフィルターがかかった後に計算されます。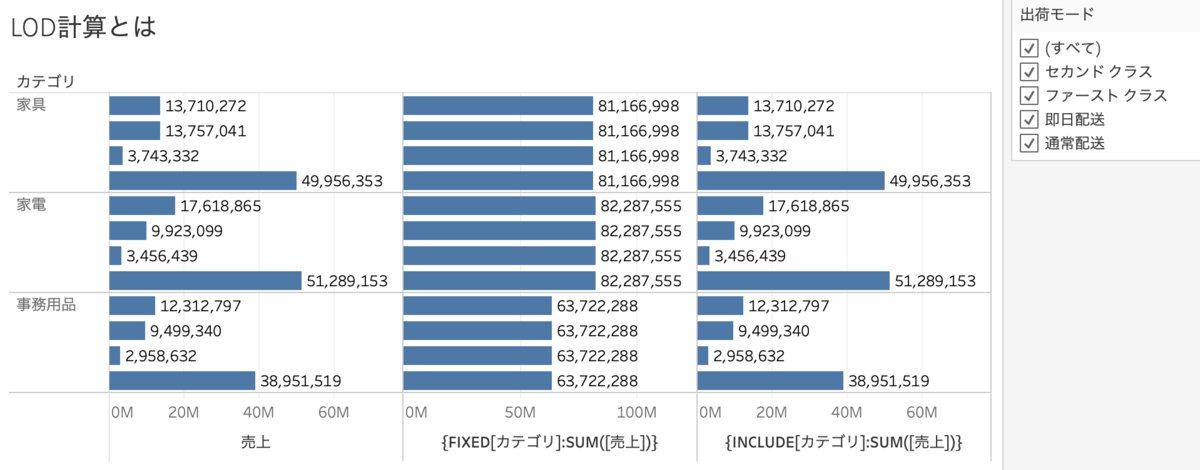
上の写真のように、
{FIXED[カテゴリ]:SUM([売上])}
{INCLUDE[出荷モード]:SUM([売上])}をそれぞれビューに入れます。
以下のように出荷モードでフィルター(ディメンションフィルター)をかけるとEXCLUDE計算だけ数字が変わることがわかります。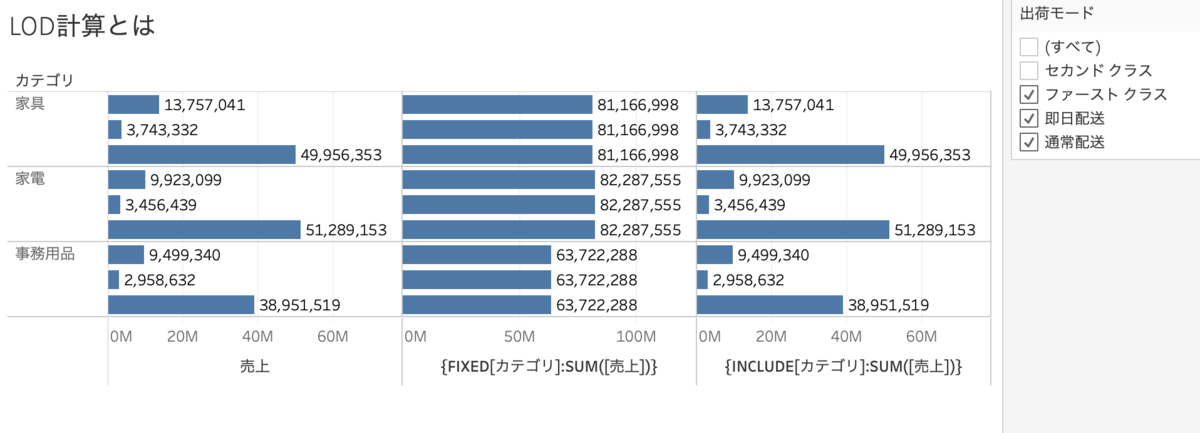
これは裏側で以下のようなことが起こっています。 繰り返しになりますが、ディメンションフィルターの後にINCLUDE計算は集計されます。
繰り返しになりますが、ディメンションフィルターの後にINCLUDE計算は集計されます。INCLUDE計算の例
「ビュー内のディメンションを考慮した○○(ディメンション)ごとの集計関数□□の△△(集計関数)」
下の例を見て、口に出してガンガン練習しましょう。
→ビュー内のディメンションを考慮したカテゴリごとの平均利益の合計
・SUM{INCLUDE[カテゴリ]:COUNTD([顧客id])}
→ビュー内のディメンションを考慮したカテゴリごとの一意の顧客id総数の合計
・{INCLUDE[顧客id]:MAX([オーダー日])}
→ビュー内のディメンションを考慮した顧客idごとの最終オーダー日
(集計関数以下が「日付型」のため、このFIXED計算も「日付型」になります。よって、非集計として、式の前に集計関数がつくことはありません。)
【Tableau】LOD計算とは?〜FIXED計算編〜

LOD計算~FIXED計算編~です🔥🔥🔥
FIXEDが理解できればこっちのもんです!
LOD計算の概要はこちらです。
kaodora.hatenablog.com
FIXED計算の特徴
1.FIXED計算は宣言したディメンションで集計します。
{FIXED[顧客id]:AVG([売上])}
このFIXED計算は顧客idごとの平均売上です。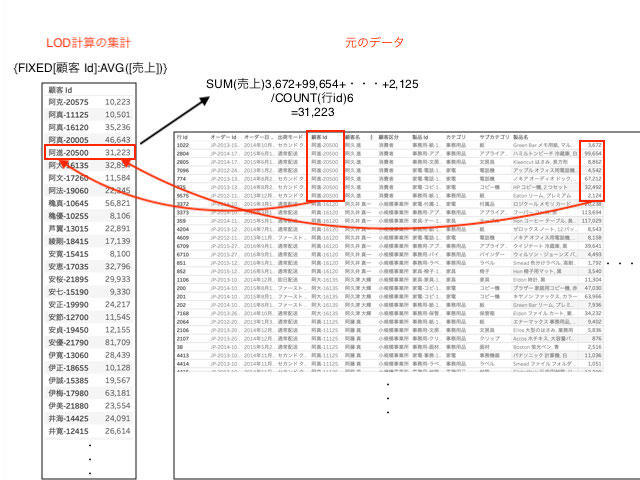
しかしLOD計算は非集計として扱われるため
AVG{FIXED[顧客id]:AVG([売上])実際ビュー上では集計関数のついたこのような式になります(デフォルトは合計)
FIXED計算は
「○○(ディメンション)ごとの集計関数□□の△△(集計関数)」を出すと覚えましょう。
よってこの式は顧客idごとの平均売上の平均となります。
(平均したものを平均というのはおかしいのですが・・・。)
2.FIXED計算は宣言したディメンション以外のものを無視します。
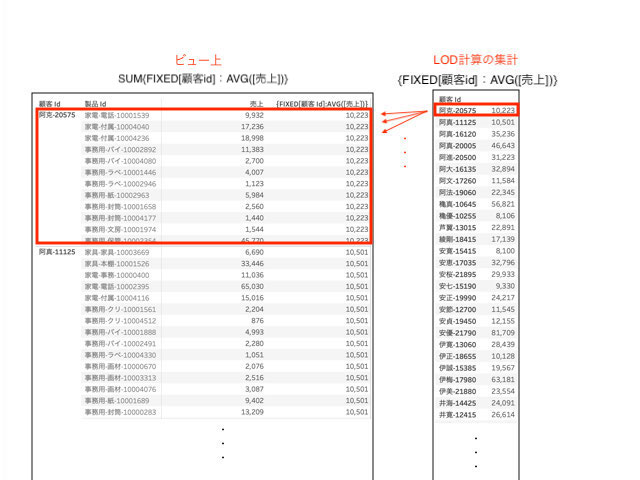
上の図にあるように、FIXEDで集計した式を顧客id,製品idの上に載せても
全て同じ数字になり製品idごとの売上にはなりません(製品idでは集計しない)
他のLOD計算はビュー上にあるディメンションを考慮しますが、FIXED計算はビュー上のディメンションを無視し、ビューに対して独立しています。
3.FIXED計算のみディメンションとして働きます
FIXED計算はLOD計算の中で唯一ディメンションとして働きます。
そのため、FIXED計算はビンにすることができます。
4.FIXED計算とフィルターの関係
同じLOD計算でもフィルターのかかる順番は違います。

地域ごとの売上と{FIXED[地域]:SUM([売上])}を並べます。
ではこれに都道府県のフィルターをかけます。(ディメンションフィルター)
この場合は除外フィルターです。
ディメンションフィルターをかけても、売上の数字が変わるのに対して、FIXED計算の数字は変わりません。
FIXED計算はディメンションフィルターの影響を受けないことがわかります。
では、上の棒グラフに利益をフィルターに入れてみましょう。(メジャーフィルター)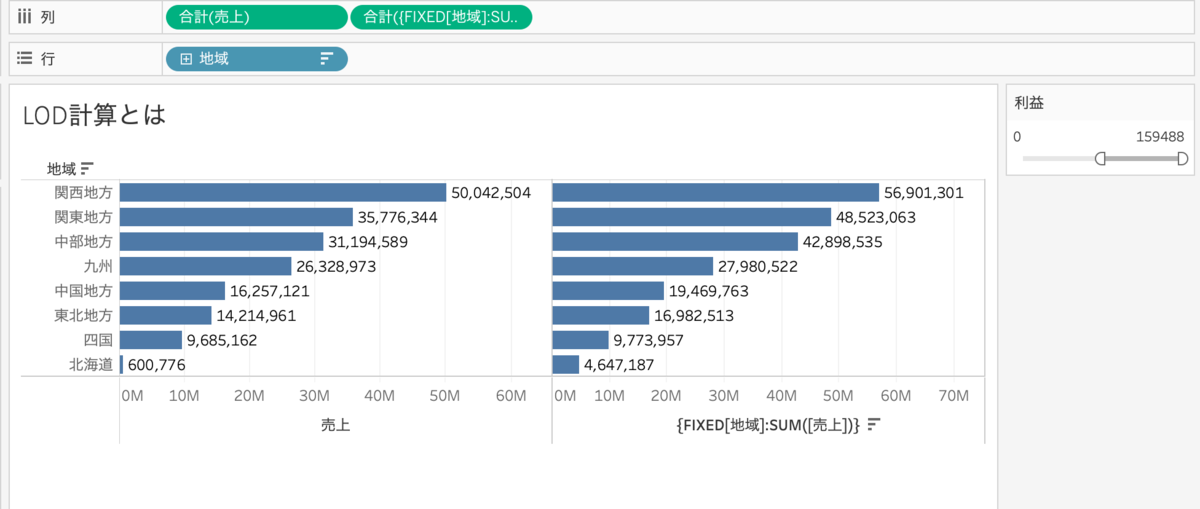
メジャーフィルターをかけても、売上の数字が変わるのに対して、FIXED計算の数字は変わりません。
FIXED計算はメジャーフィルターの影響を受けないことがわかります。
FIXED計算の例
FIXED計算は先ほどもありましたように、「○○(ディメンション)ごとの集計関数□□の△△(集計関数)」です。
下の例を見て、口に出してガンガン練習しましょう!
・SUM{SUM([利益])}
→データ内の全ての利益の合計の合計
(ディメンションを宣言しないで、データ内の全ての□□を出したい場合は、FIXEDを省略することができます。)
・SUM{FIXED[カテゴリ]:AVG(利益)}
→カテゴリごとの平均利益の合計
・SUM{FIXED[カテゴリ]:COUNTD([顧客id])}
→カテゴリごとの一意の顧客id総数の合計
・{FIXED[顧客id]:MAX([オーダー日])}
→顧客idごとの最終オーダー日
(集計関数以下が「日付型」のため、このFIXED計算も「日付型」になります。よって、非集計として、式の前に集計関数がつくことはありません。)
・SUM{FIXED[カテゴリ],[顧客id]:SUM([売上])}
→カテゴリ、顧客idごとの売上合計の合計
(宣言するディメンションを複数入れることができます。→INCLUDE計算に代用可能)
次回INCLUDE編です🧊🧊🧊