【Tableau】DATASaber:DATA Platform(Ord4)解説
はじめによんでください。
kaodora.hatenablog.com
DATA Saber Boot Camp Week1 "Platform 101: Data Platform〜すべての人が安心してデータを使える土台を作る" - YouTube 美しいビュジュアライゼーションの目的は、ストーリーを見出すことではなく、人にシェアしてアクションしていくこと。 データリテラシーを持った異なるスキルの人々が、自らの役割に応じて、同じ土台の上で自分が最も力を発揮できる仕事をしていることが大切! 安全に美しく使いやすい状態でデータが同じところに置いてあるところで、みんなが安心してデータを使うことができる。 ①分析結果を求めている「Task」を持っている人が自分でデータを探索することができず、他人に分析やレポーティングを依頼して作ってもらっている状態 セルフ分析ができるようになれば・・・ 機能 効果 しかし、データを見ることで すべての人がデータを見て理解した上で会話することで Creator Explorer Viewer 同じ土台の上で役割に応じて、自分が最も力を発揮できる仕事をする。
DATA Saber Boot Camp Week3 "Platform 102: Data Platform - History~データは見られるほど美しくなる" - YouTube
DATA Saber Boot Camp Week3 "Platform 102: Data Platform - Future~すべての人が安心して生きられる大地を目指して" - YouTube
データは同じ土台に
データは同じ土台になければならない。(データを一元管理する)
同じデータでないと・・・
①ばらばらに点在したデータをそれぞれが見ている場合、まずお互いの見ているデータが一致していることから確認しなくてはならないから
②同じ場所にあるデータを見ていないと、共通の事象を見ている信頼を持ってお互いに話すことができないから
③分析のためのデータを探すことに時間がかかってしまい、Data Driven Cultureの浸透を進める妨げになってしまうから
現場部門、IT部門双方のコミュニケーションと寄り添いが重要。
(データ流出の恐れがある)twbx.をEメールで共有するところから、データソースとワークシートを分けてパブリッシュをしてみよう!レポートファクトリー
②レポート作成依頼を受けるメンバーが過剰な依頼数に忙殺され、すぐに分析結果を依頼主に返すことができない状態
③依頼からレポート完成までに時間がかかり過ぎて、もはやレポートが完成する頃にはその分析結果が不要になっている状態
↓脱レポートファクトリー!!みんながセルフ分析を目指そう。
セルフ分析ができないと・・・
自分の持っている課題や質問を人に伝えて解決してもらうのは困難
自分自身で判断のための情報を得られないとビジネスの判断が遅れてしまう
自分の問いかけに瞬時にデータを通して答えを得るとき、即座に次の問いや解決方法を思い浮かべたり、試したりできる!
思考のフローに乗るための自身の思考や操作に対する瞬時のフィードバックが得られる!
自分の手を動かして初めて理解できる事柄がたくさんある!Tableau Server/Onlineの機能・効果
データを活用する理由

会議等で意見が食い違った時、どうしますか。
データを見ないで判断すると・・・
Creator、Explorer、Viewer
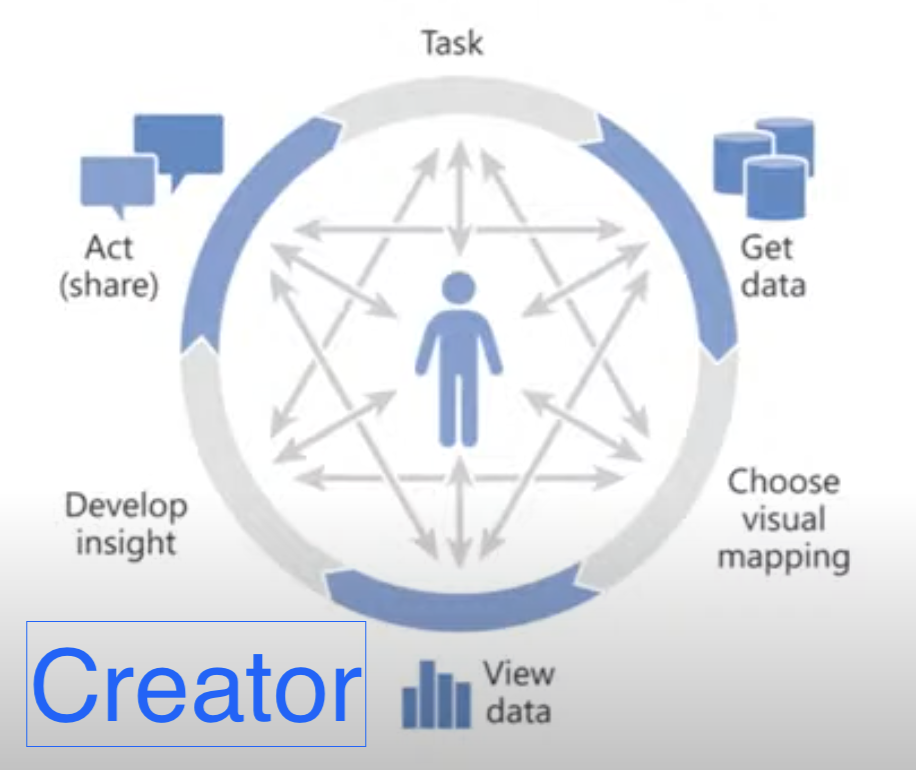
[¥102,000]インサイトを引き出すためのパワフルなTableau製品スイート、エンドツーエンドの分析ワークフローを支援
常に新たな視点を持ち創造する人

[¥60,000]信頼されたデータの探索、セルフサービス分析機能を使ったデータ分析で、質問の答えを速くデータから引き出せる。
常に探究心を忘れず、世界のことを知りたいと思い続ける好奇心を持つ人

[¥22,000]ダッシュボードとVizの参照、及び操作をセキュアで使いやすいプラットフォームで行える
美しい数々のViewを見て心を動かし、アクションしていく人々
(データドリヴンな組織とはすべての人がTableau Desktopでドラッグアンドドロップしながらデータを深堀することではない)
【Tableau】連続と不連続

連続と不連続はTableauを始めてから最初につまずきました。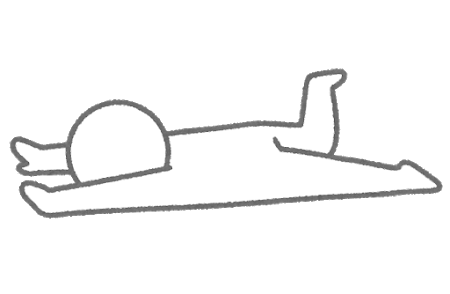
わからないままにしていて、問題を解く時にその場その場で考えてやっていたのですが
DATASaberの試験の前にこのままではダメだと
いろいろな方がまとめてくださった動画、本、ブログで役に立ったことをまとめました。
連続・不連続とは
上の動物達を見てください!
連続の動物達は繋がっていて、不連続の動物達はバラバラですよね 。
つまり、連続は繫っていて、不連続は独立しているのです。
ではTableauで見てみましょう。
(連続)
月(オーダー日)連続の軸を触ってみると、全体を選択できます。連続は一つに繫っているからです。
(不連続)
月(オーダー日)連続の軸を触ってみると、○年○月一つ一つを選択できます。不連続は一つ一つが独立しているからです。
そして上で見るように
連続は緑 
不連続は青 
で表されています。
連続・不連続の切替え
では、データペインを見ると以下のようになっていませんか。

これを見ると、ディメンションは不連続でメジャーは連続なんだ!と思いますよね。
これは半分正解です。ディメンションは不連続で、メジャーは連続で使われることが多いからです。ここではTableauが判断して連続・不連続を振り分けてくれています。
しかし半分不正解な理由は、連続・不連続は自分で簡単に切り替えることが出来るからです。
(切り替える方法①)
データペインで右クリックしてそれぞれ、連続(不連続)に変換をクリックします。

↓

オーダー日を見るとディメンションの中でも緑に、割引率はメジャーの中でも青になっています。
(切り替える方法②)
シェルフに入れてからも右クリックで切り替えることが出来ます。

(切り替える方法③)
ビューを作る際、ディメンション*をcommandキーを押しながらドラッグ&ドロップします。すると下のような画面が出てきて、連続・不連続を選択することができます。

*メジャーをcommandキーを押しながらドラッグ&ドロップすると集計・非集計を選択することができます。
どんな時に連続・不連続を使い分けるか
連続
数値、日付を扱う時

赤い丸の部分に注目してください。連続の数量は軸として使われています。
つまり数字の順番が決まっているような時は連続として使われます。
不連続
数値、日付、文字列を扱う時

赤い丸の部分に注目して下さい。不連続の数量はヘッダーとして使われています。
それぞれが独立してデータを示す時には不連続として使われます。
連続・不連続と並び替え
並び替えにおける連続・不連続の違いを見てみましょう!
(連続)
(不連続)
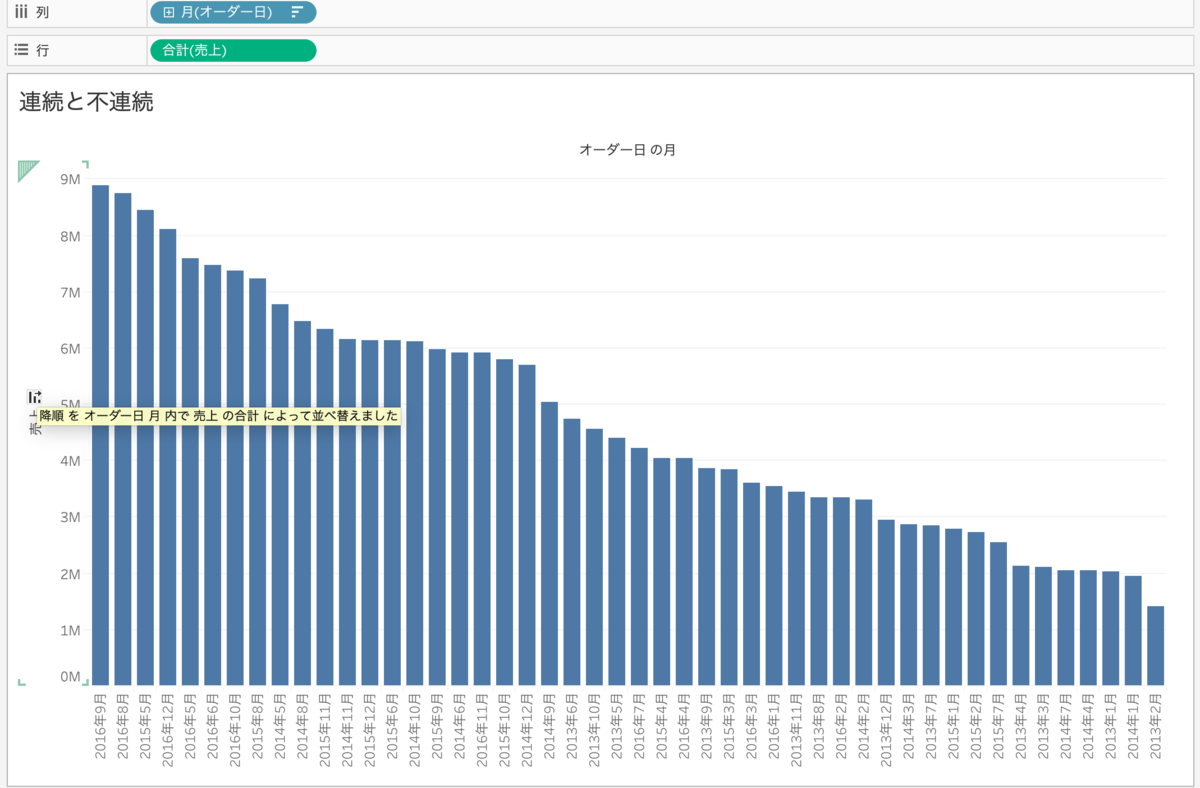
連続は並び替えすることができません、不連続は並び替えすることができます。
連続は一つに繫っているため、並び替えをするということはありえないのです。
不連続は独立しているそれぞれを並び替えることができます。上の図でいうと、売上高い月順に並び替えていることになります。
連続・不連続とリファレンスライン
(連続)
 →
→  (不連続)
(不連続)
連続はリファレンスラインを追加することができますが、不連続はリファレンスラインを追加することができません。
不連続はヘッダーなので、ヘッダーにリファレンスラインを入れるということはありませんよね。
連続・不連続と色
売上の大きさを色でも表現したいと思います。*
*ここでは日付ではなく売上の連続・不連続を比べています。
(連続)
(不連続)

連続ではグラデーション*で、売上が大きければ青に近く小さければオレンジに近い色になっています。
不連続では売上が単独で認識され、一つ一つに色がついています。売上の大小と色相に関連がありません。
このように数値を色で示したい場合は連続の方が良さそうですね。
下のように売上を各年で表したい時などは不連続で色をつけると良さそうです!
*連続もステップドカラーを使うことで、色を段階に分けることができます。

連続・不連続見た目の違い
(連続)
(不連続)
連続は2013年の売上が2013年と2014年の間に棒があります。
不連続は2013年の売上が2013年の真上に棒があります。
連続は軸の上に位置していて、不連続は独立しています。
まとめ
連続は緑色。
一つに繫っていて、軸になる。
数値や日付の時に使われる。
並び替えできない。
リファレンスライン追加できる。
色に入れるとグラデーションになる。
チャートは軸と軸の上に位置する。

不連続は青色。
一つ一つが独立していて、ヘッダーになる。
数値、日付、文字列の時に使われる。
並び替えできる。
リファレンスライン追加できる。
色にいれると単独の色になる。
チャートは軸の真上に位置する。
【Tableau】DATASaber:HandsOn - Intermediate I(Ord3)解説
はじめによんでください

Q1
Ord3(1) pic.twitter.com/vSGnnp7cV6
— 動画掲載用 (@Kaodoramichan) 2020年12月19日
地域マネージャーをとるために、関係者シートを結合します。
都道府県に地理的役割を与えて、まず都道府県ごとの利益を出します。
それから地域ごとの利益を出します。
ダッシュボードで2つのシートを並べます。都道府県の方「フィルターとして使用」すると、もちろんその選択した都道府県が上のシートに反映されます。
しかしフィルターをかけたいシート(地域の利益シート)に戻って、フィルター編集から、除外にチェックを入れます。すると、選択した都道府県を除外した利益が、地域ごとの利益に反映されます。ベンリデスネ👀
地域ごとの利益に地域マネージャーも入れて、各地域で試してみましょう!
(おまけ)
Ord3(1)-2 pic.twitter.com/p2q6LE6dsW
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
各地域の赤字の県を触ってみて、なんとなく中部地方かな?関東地方も良い線いってるかな?と少し曖昧じゃないでしょうか。
そこで、除外される前の利益との差を明確に出してみようと思います。
{FIXED[地域]:SUM([利益])}
地域ごとの利益を出してねという式です。「地域ごとの利益」という名前にします。
この式を使えばフィルターがかかってもそれに影響されません。
合計(利益)と合計(地域ごとの利益)を複合グラフにして、メジャーネームをサイズと色に入れます。フィルターをかけると、合計(利益)は除外したものを返しますが、合計(地域ごとの利益)は変わりません。

これにはTableau内でのフィルターのかかる順番が関係しています。
今回使ったFIXED計算(FIXED計算)は,都道府県のフィルター(ディメンションフィルター)よりも先にかかるので影響しないということですね。
明確に元との差がわかりました!ここまで来たので数字も出してみましょう。
SUM(利益)-SUM(地域ごとの利益)
という式を作ります。名前は「元の利益との差」にします。
別のシートに地域ごとの元の利益との差を出し、ダッシュボードに追加します。フィルターをかけてから、先ほどと同じようにシートに戻って、フィルター編集で除外にチェックをつけます。それからヘッダーを外します。
これで明確に赤字の1県を除外して大きく利益が上がった地域が出せました!
Q2
Ord3(2)-1 pic.twitter.com/mKTKe4I4NA
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
メーカー情報を取るためにサンプル - スーパーストア - メーカー情報.tdsxをブレンディングします。シートに直接ドラッグ&ドロップでOK。今回は製品idという同じ項目があるので、別途接続の編集をしなくて良さそうです。
売上のメーカー分布を出して、それをカテゴリで分け、利益で色をつけます。
(おまけ)
Ord3(2)-2 pic.twitter.com/pOE1mcOL0e
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
メーカーは今別のデータソースに入っていますが、注文(サンプルスーパーストア)に取り込むことができます。結合キーとなっている製品idを使います。
注文(サンプルスーパーストア)の製品idをビューにおいて、メーカーを並べます。
*この時製品idが鎖でつながっていることを確認してください。![]()
メーカーを右クリックして、「プライマリグループの作成」を選択しグループを作成すると、取り込むことができます。
LOD計算をする際、同じデータソース内のものでないとできないので便利です!
Q3
Ord3(3) pic.twitter.com/qn7yAw48Hf
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
ここでは2016年、2015年の売上を比較するために計算式を使います。
IIF(DATEPART('year', [オーダー日])=2016,[売上],NULL)
もしオーダー日(年)が2016だったら、売上を返してね。じゃなかったらNULLね。という式です。DATEPARTは指定した日付単位の数値を返す関数ですが、打つのは手間だと思うので、ビューに年で落としてから計算式に入れると楽です👍
同じものを2015年で作ります。
それから2016年の売上をカテゴリごとに出して、リファレンスラインの追加から分布で2015年の売上を入れます。カテゴリごとの出したいので必ずセルで設定です。問題文に95%は超えていますか、とあるので今回は95,100にしましょう。
最後に
SUM(2016年の売上)>SUM(2015年の売上)
2016年の売上が2015年の売上より大きかったら真、あとは偽にしてね。というブール式を色に入れます。
家具は2015年の売上を超えていませんが、95%は超えています。
Q4
Ord3(4) pic.twitter.com/4t3vciOhT0
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
サブカテゴリごとに1行単位の利益を出します。
テキストで最大値のみ表示にすると電話機が1番大きい利益を出していることがわかります。さらに、サブカテゴリごとの合計利益を出します。簡易表計算のランクで、電話機のみに表示させてみると、8位とそれほど好調でないことがわかります。
利益と合計(利益)の説明はこちらから!
(オプション問題1)

Ord3(4)オプション問題1-1/2 pic.twitter.com/KV5RibORfP
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
ランクチャートを作成します。
まずは赤字レコードを除外した利益を表す式を作成します。
IIF([利益]>0,[利益],NULL)
もし利益が0以上だったら利益を出してね、それ以外はNULLねという式です。「0以上の利益」という名前をつけます。
そして、利益と0以上の利益を複合グラフにしてから、それぞれでサブカテゴリのランキングを作ります。
ランクチャートを作るときの注意点ですが、Tableauの軸は上から順に並ぶので軸を反転させなければいけません(1(位)を上にしたいですよね)
そしてメジャーバリューを複製して、片方は円にもう片方は線にします。そして二重軸にしますが、同じものを複製して二重軸にするときは軸の同期をしなければなりません。円と線がぴったり合わなくなるからです。
この時点でチャートを触れば、サブカテゴリごとのランクの変動はわかりますが、ディテイルを作っていきます。
Ord3(4)オプション問題1-2/2 pic.twitter.com/EFrYONf3HW
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
メジャーバリューを円のテキストに入れます。
位置を調整します。小数点以下を0にして、数字の前に#を入れます。円の色を白にして枠線を黒にします。
また次の式を線の色に入れます。
RANK(SUM([利益]))-RANK(SUM([利益が0以上])) 「ランクの差」
これでランクの増減を色でも見ることが出来ます。
サブカテゴリとランクの差を線のテキストに入れて、テキストの中身を見やすいように変更します。
テキストの位置を調整し、ヘッダーの非表示にします。
最後に分析→表のレイアウト→詳細から下にあるメジャーネームを上に表示させたら完成です。
このランクチャートはお師匠に教えていただいた技でした!さすが綺麗です😂
(オプション問題2)
Ord3(4)オプション問題2 pic.twitter.com/W8J6LPy8h6
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
Q4と同じようにサブカテゴリごとに1行単位の利益を出します。
そして、赤字レコードのもののみを見たいのでフィルターで利益が0以下のもののを表示させます。さらにメーカーで分け、利益をカウントしてメーカーの数(赤字レコードを出したメーカーごとの回数)を棒グラフで表します。
アップルやサムスンが多そうです。
Q5
Ord3(5) pic.twitter.com/H4UWnxrTjx
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
製品名の売上を出して、フィルターの条件で上位10位に絞ります。
フィルターに入れた製品名を右クリックするとセットを作ることができます。
さらにそれを複製して下位10位のセットを作ります。
データペインで2つのセットを選択して、「結合セットの作成」をします。
作成の際結合の内容を設定します。
結合セットをフィルターに入れて、さらにカテゴリで分けて製品の利益を見ます。
事務用品の利益は他のカテゴリに比べて小さいのでうまく比べることができません。そこで赤字の製品数を知りたいので、利益をフィルターに入れて利益が0以下のものに絞ります。そうすると、事務用品に赤字に製品が多いことがわかります。
数を明記するためにペイン(下)で、ランクを入れます.
Q6
Ord3(6) pic.twitter.com/eliefhAeOs
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
サブカテゴリごとに売上を出して、合計(利益)で0以上にします。
Q7
Ord3(7) pic.twitter.com/8u5f7ekT0F
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
サブカテゴリごとの売上を出して、(利益)で0以上にします。
Q6,Q7ともに集計・非集計の考え方だと思うのでよかったら過去の記事を読んでみてください!Q4の欄にリンクを載せました!
Q8
Ord3(8) pic.twitter.com/1imEO4qWkQ
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
黒字顧客をセットで設定します。
顧客名の利益を出して、顧客名をフィールドに入れて利益が0以上(>=)のものに絞ります。そこからセットを作成します。
オーダー月ごとに売上を出し、作成したセットを色に入れます。
簡易表計算の合計に対する割合を表(下)で設定します。テキストを表示させて、黒字(IN)は黒色、赤字(OUT)は赤色に色を変更します。
Q9
Ord3(9) pic.twitter.com/gZGOKZlEF9
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
Q3で作成した2016年の売上を使います。
オーダー月ごとに売上を出し、カテゴリを色に入れます。
売上を複製し、簡易表計算で累計にします。これらを二重軸にすると、色が6色になります。
棒グラフの方で、2015年の売上を詳細に入れ、リファレンスラインをセルごとに追加します。線は消して、下の塗りつぶしにします。
Q10
Ord3(10) pic.twitter.com/on8cRqGuRb
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
顧客名における売上と利益の散布図を作成し、クラスターは利益の条件で5つに分けます。利益の低いクラスター4を選択してセットを作成します。
顧客名における割引率(平均になっている確認してくださいね!)と売上の散布図を作成し、クラスターは割引率の条件で5つに分けます。割引率の高いクラスター4を選択してセットを作成します。
データペインで2つのセットを選択して結合セットを作成します。
割引率は高いけど、利益は低くないという言葉に気をつけて条件を設定します。
顧客名における売上と利益の散布図を作成し、結合セットをフィルターに入れます。
さらに顧客区分で分けて、チャートを棒グラフに変更、利益を色に入れます。黒字は黒色に、赤字は赤色にします。
消費者区分は比較的黒字を出せているようです。
Q11
Ord3(11)1/2 pic.twitter.com/ZKFdQFnj5b
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
予算を取るために、サンプル - スーパーストア - 予算をドラッグ&ドロップで入れます。データをみてみると綺麗なデータではなさそうです。
そこでデータインタープリターを使用して、Tableauに整えてもらった後、ユニオンを新規作成してそれぞれをくっつけます。
それから年月が列に並んでいるのでピボットして、新たな年月と予算を作成します。
年月は日付フィールドに変換させましょう。
問題文にあるように、年月に2年足す計算式を作ります。注文(サンプルスーパーストア)とブレンディングさせるために、名前はオーダー日にします。
DATEADD('year',2,[年月])
DATEADDは指定した日付単位に増分を追加した日付を返す関数です。つまりこの式は、年月に2'年'足してね、という式になります。
それから、ブレンディングのためにエリアを地域に、製品カテゴリをカテゴリにしてテクノロジーを家電に変更します。
Ord3(11)2/2 pic.twitter.com/3RCiFPzO9O
— 動画掲載用 (@Kaodoramichan) 2020年12月21日
オーダー年、地域、カテゴリごとに売上を出します。
予算を詳細に入れて、リファレンスラインの追加から分布をセルごとに入れます。
問題文に従って、50,100とします。
そしてカテゴリを家電に絞ります。
合計(売上)>合計(予算)の色を入れて、最後に地域を北から順に並べます。
【Tableau】DATASaber: Visual Best Practice I(Ord2)解説
はじめによんでください

Visual best practice l(Ord2)は私自身少し苦労しました!
しかし、KTさんの動画を見て視覚的分析のベストプラクティス: ガイドブックを読めば解ける問題だと思います。疑問を感じた点は、同じApprenticeの方達とディスカッションもしました。
ここでは、1問1問解説するのではなく口頭試験前にまとめた私のメモを載せたいと思います。
Visual best practiceと一言で言っても奥が深すぎます・・・。追記多発の予感😂
ビジュアライゼーションを作る順番
経時的な傾向を示す
○折れ線グラフ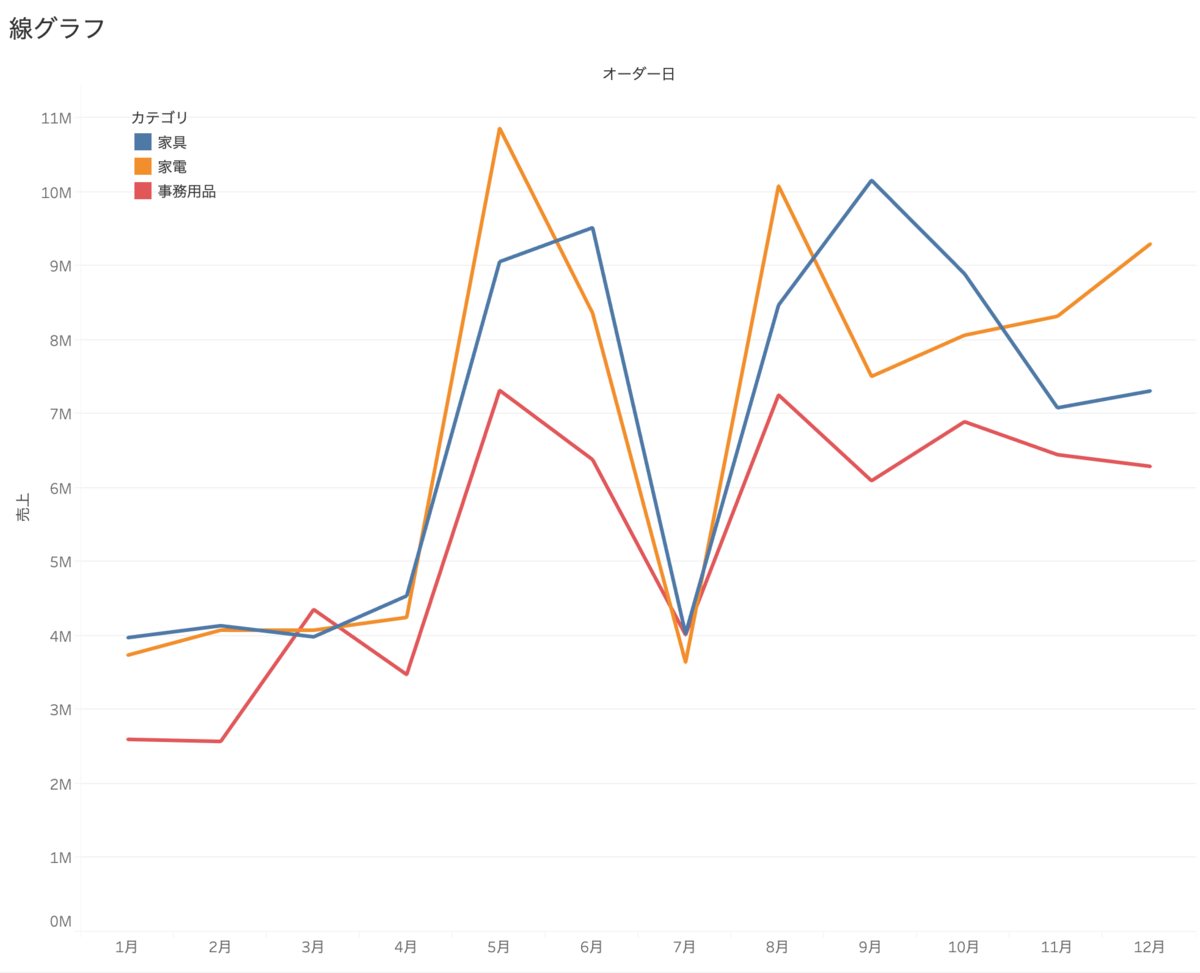
カテゴリごとの傾向、カテゴリ間の傾向の違いがわかる。
全体的な傾向はわからない
↓棒グラフか面グラフにする
○棒グラフ
全体的な傾向を示し、各カテゴリの貢献度を見ることができる。
各月を1つのパターンとしている。
○面グラフ
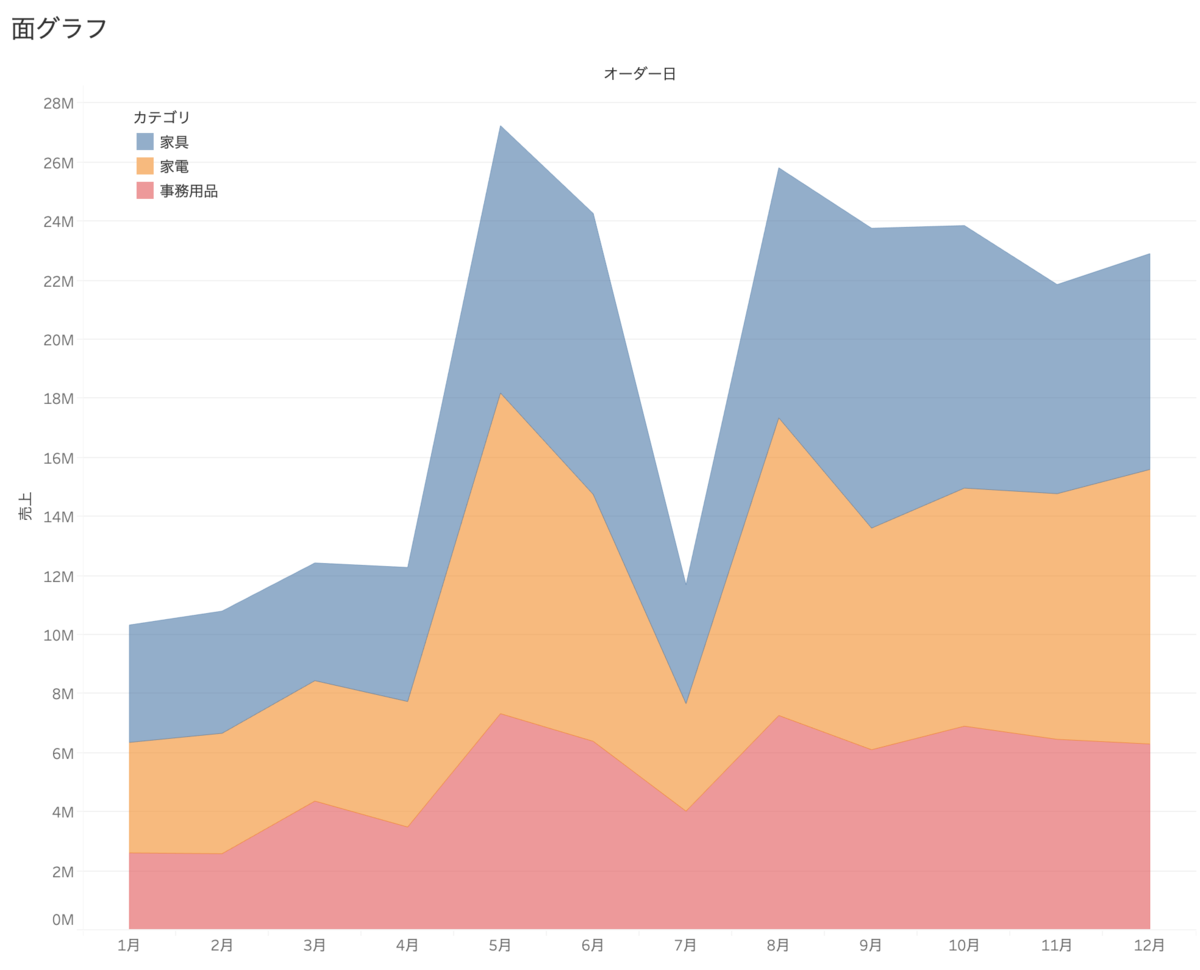
棒グラフと同様に全体的な傾向を示し、各カテゴリの貢献度を見ることができる。
各カテゴリを1つのパターンとしている。
比較とランク付け
○棒グラフ

定量的な値を1つのベースライン上での長さとしてエンコードすることによって、とても簡単に値を比較することができる。
相関性
○散布図

メジャー間の関係性を認識することができる(関係性を保証するものではなく、可能性を示唆する程度)
しかし他の要素を加えると分析の妨げになることがある。
○棒グラフと線グラフの組み合わせ
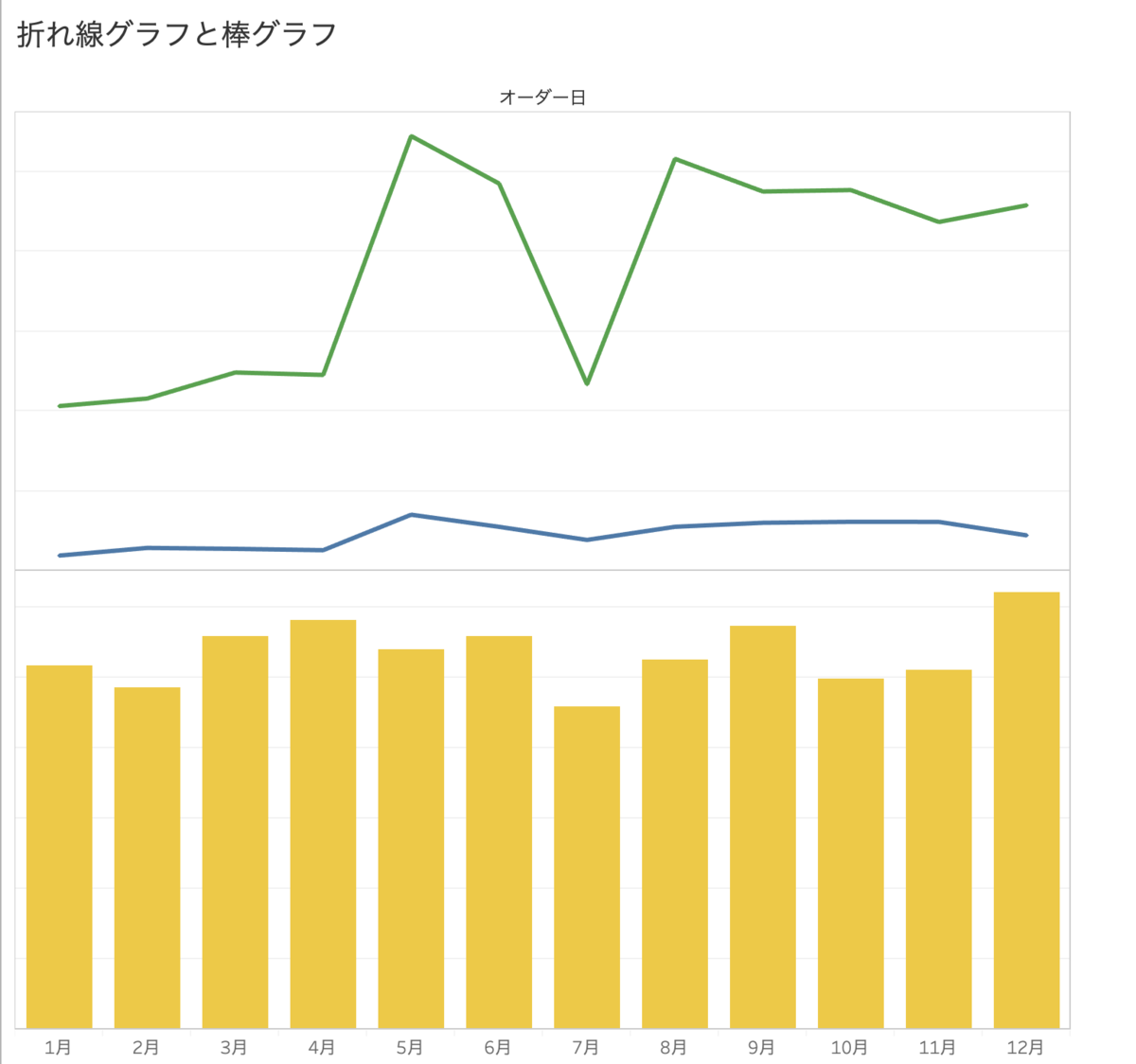
上2つの傾向の比較に注目するように促すことができ、棒グラフからは相関性の分析を妨げることなく意思決定を行うことができる。
分布
○箱髭図

複数の分布を表示するのに優れている。サブカテゴリごとの箱の大きさを比較することができる。この場合サブカテゴリごとに単価の幅があるか、数量に差がある可能性がある。

異なるグループのデータがどのように分布してるかを示す。
この場合は、売上をある単位(1000円)でデータを分けて、その区分ごとのオーダー数を示している。サブカテゴリごとの貢献度を見ることもできる。
一部と全体との関係
○円グラフ

よく使われるが不向き。しかし日本人は見慣れている。
色がないと比較できない、隣り合うものしか比較できない、数が多いと比較が困難、角度の比較は困難、スペースを大幅に取る。
しかし、拮抗する2つのものを比較するのに円グラフは最適(ドーナツチャート)
○棒グラフ

合計に対する割合を使う。円グラフよりはわかりやすいが、数が多いと比較が困難、色がないと比較できないという点は同じ
地理的データ
○マップ

マップ情報の詳細を示した棒グラフや折れ線グラフ、クロス集計等を追加すると最良の資料になる。
その他
[最重要データの強調]
最も重要なデータをX軸とY軸に設定し、さほど重要でないデータを色やサイズや形状に設定するのが一般的
 重要な順番
重要な順番
[読みやすいビューの作成]
縦方向にしか表示できないような長いラベルがある場合はビューを回転させる
[ビューの整理]
ブレットグラフは棒グラフに参照線を組み合わせることで実際の数と目標の数を視覚的に比較できるようになる。
[ビューへの過重な負荷の回避]
数多くのメジャーとディメンションを1つのビューの重ねて表示するのではなく、複数のグラフに分割するべき。
[1つのビューで使用する色と形状の数を制限]
色と形状の数は7~10種類に制限する
色について→多くの文化では、緑はポジティブ、赤はネガティブを暗示する
[フォント]
(推奨フォント)
・Trebuchat MS Verdana
・Arial
・Tahoma
・Times New Roman
・Lucida sans
1ページに使用するフォントの色は2,3色にする。隣あうテキストフォントには複数の属性を変更することは避ける
良い 変更例 悪い変更例
[ツールヒント]
メジャー名はわかりやすくする(カウント(飛行機)→飛行機の台数)
表示する全ての数値には単位をつける
[インテリジェントな軸の作成]
○固定軸
○軸のグリッド線
○軸のラベル
[ラベル]
○選択項目にラベル
○最小値と最大値にラベル
○ハイライトにラベル
○行末にラベル
ダッシュボード
[ダッシュボードの種類]
○説明型
作成者の伝えたい内容が表現されているダッシュボード。意見が明確であることが必要
○探索型
ビューアー自身にインサイトを得てもらうダッシュボード。中立であることが必要
効果的なダッシュボードを作成するための 10 のベストプラクティス
(このホワイトペーパーも読んだ方がいいです!)
(1)ユーザーを知る
(2)ディスプレイのサイズを考慮する
(3)読み込みを速くするように配慮する
(4)スイートスポットを活用する
(5)ビューと色の数を制限する
(6)インタラクティブ性を強化して発見を促す
(7)最大値最小値までの書式設定
(8)ストーリー内のストーリーである「ツールヒント」を活用する
(9)不要なものを除去する
(10)ダッシュボードの使いやすさをテストする
[使いやすいダッシュボード]
○最も重要なビューをダッシュボードの上部もしくは左上端に配置
○1つのビューが次のビューをフィルターしていく連鎖式である場合、上から下、左から右に配置する
○ダッシュボードに配置するビューの数は3つもしくは4つ
○カラーパレットは2つまで
○フィルターが複数ある場合はレイアウトコンテナーでまとめる
○凡例が全てのビューの適用される場合は、全てのフィルターと一緒に配置する。一部に適用される場合は、できるだけそのビューに近いところに配置する。
[ハイライト]
たとえ複数のビューにまたがっていても、特定のエリアやカテゴリの値の関係性を簡単に提示することができる
[フィルター]
データを様々な角度から検討したり、さらに詳細レベルにデータをドリルダウンする
1.クイックフィルター
2.ビューをフィルターとして使用
3.フィルターアクション
4.パラメータ付きのフィルター
[URLアクション]
Preattentive Attribute
向き 幅 長さ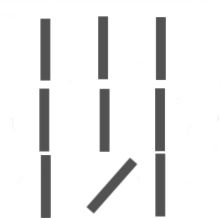


囲い サイズ 形状 


色相 彩度

空間グループ 位置

形状→サイズ→色→位置の順番で重要度が上がっていく
[分類](アジア・ヨーロッパ・アフリカ)
形状・色相
[順序](金・銀・銅)
位置・サイズ・彩度・色相・形状
[量](10kg・25kg・100kg)
位置・長さ・サイズ・彩度
【Tableau】集計と非集計②〜計算式でなんでSUMが必要なんですか?〜

①はこちら〜
kaodora.hatenablog.com
だんだん慣れてくると自分で計算式を書く場面がありますよね。
この間、社内勉強会を行った時に利益率を出す場面がありましが
意気揚々とこの式「SUM([利益])/SUM(売上)」を出しました!
すると
「なんでSUMが必要なんですか??」
 「えっと、えっと・・・」
「えっと、えっと・・・」
うまく説明できなかったんです😢
いつでも引き出せるようにしないとダメですね。反省です。
いつの日かまた聞かれたときのために、ここで練習します・・・!
まずは事務用品の利益、売上、[利益]/[売上]、SUM(利益)/SUM(売上)
を出してみます。

ゼンゼンチガイマスネ!
それぞれどんな計算がされているのか見てみましょう。
どん!
どどん! と粒度を一番細かくしました。
と粒度を一番細かくしました。
それぞれの総計をみてみると
AVG[利益]/[売上]の総計4.52%は、列上から下まで全部(18.99%~49.00%・小計は無視してね)の平均の数字です。
SUM([利益])/SUM([売上])は総計は31.96%は、利益の総計334,770を売上の総計1,047,340で割った数字です。
小計の方も同じように計算されています、確認してみてください!
[利益]/[売上]はオーダーIDごとに1行1行計算したものを、平均しています。メジャーとして合計やカウントにすることができます。(行レベル計算)
![]()
SUM([利益])/SUM([売上])は利益、売上それぞれを全部足してから平均しています。すでに集計しているものを計算しているので、これ以上は計算できず、メジャーの部分は消えて「集計」という表示になります。(集計計算)

「事務用品の利益率を見たい!」
となった時、お会計するごとに利益率を出してその平均を見るのではおかしいですよね。全部の利益と売上を出してから計算しないと正しい数字ではありません。

結論。
利益率出す時はSUMつけてね!!
AVG[利益]/[売上]とSUM([利益])/SUM([売上])は似て非なるものでした。
サムネイルのヒョウとチーターも似て非なるものですが、どっちがどっちでしょうか🐯
【Tableau】DATASaber:Ord解説について
DATASaberの試験が終わり、Ordの解説をしてみようと思いました!
ひとつは説明しながらVizを作る練習のため(動画は無音ですが、1人でぶつぶつ言いながら録画しています)、ひとつは1問1問のポイントを自分のために備忘録したいため、そしてデータ分析のおもしろさを知ることができたDATASaberという制度に何か貢献したいと考えたためです。
以上の目的のため、解説では解答を明記することがないように気をつけたいと思います。
そして、もしDATASaberに挑戦中の方が読んでくださったらとても嬉しいです。
そして、大切なことをお伝えしたいです。
KTさんの動画の方が100倍わかりやすいですよ
DATASaberの勉強が終わって新たな挑戦として頑張りたいと思います。

【Tableau】DATASaber:HandsOn - Fundamental(Ord1)解説
はじめに読んでください。
まずはデータ接続から、という方こちらをどうぞ!
Q1
Ord1(1) pic.twitter.com/iyyms1nr9F
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月17日
カテゴリ、サブカテゴリごとに売上を出して降順にします。
(おまけ)順位を表記する
売上をテキストに入れて、簡易表計算からランクを選択します。そのままでは全体の売上順位なので(表(横))、ペイン(横)にしてカテゴリ内の売上順位を出します。バインダーを強調させたいので、一度全てのテキストの表示をなくして、データの表示から「常に表示」を選択します。
Q2
Ord1(2) pic.twitter.com/dKsw7AEX5U
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月17日
地域ごとの割引率を出します。そのまま割引率をビューに入れると、合計になってしまうので平均に変えます。書式設定から軸、ペインそれぞれをパーセンテージに変えます。並び順を降順にして、テキストから最大値のみを表示させます。
(別解)事前に設定する
Ord1(2)-2 pic.twitter.com/9WlWDvAZSy
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
データペインの割引率の、デフォルトのプロパティから集計を平均に、数値形式をパーセンテージに変更します。 地域ごとの割引率を出し、降順にしてからテキストを最大値のみ表示させます。
Q3
Ord1(3) pic.twitter.com/FYShVIw5iC
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月17日
オーダー日(年)をフィルターに入れて、2014年に絞ります。顧客Idとカテゴリをビューに入れます。すると左下にマーク数がでます。
Q4
Ord1(4) pic.twitter.com/Ta4oMzULWO
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
オーダーidごとの売上を出します。オーダーidをフィルターに入れて、上位10に絞ります。
(別解)ランクを入れる
Ord1(4)-2 pic.twitter.com/uiqpW43BaL
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
オーダーidごとの売上を出します。売上を複製して、簡易表計算のランクを選択します。それを不連続にしてオーダーidの隣に入れます。さらにそれをフィルターに入れて、10まで選択します。
Q5
Ord1(5) pic.twitter.com/edXl7jJz0k
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
オーダー年月ごとの売上を出します。売上を簡易表計算から前年比成長率を出します。カテゴリを色に入れて、アナリティクスから傾向線を入れます。
(別解)カテゴリを行で分ける
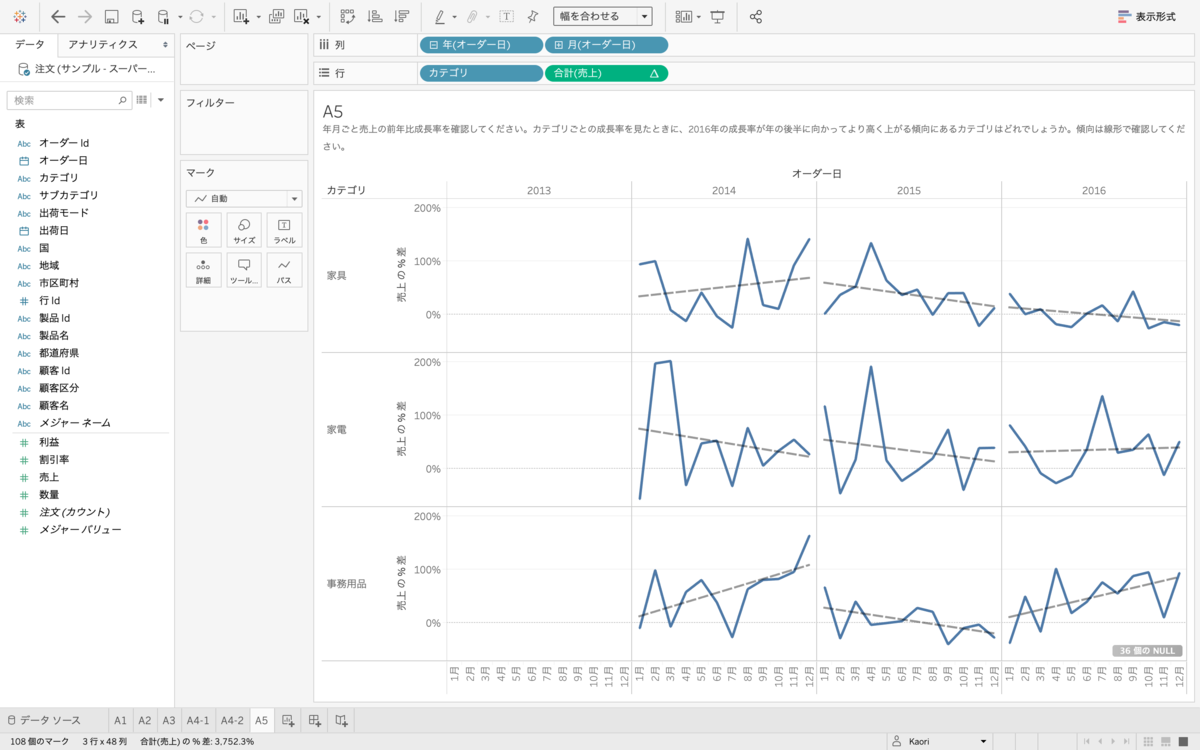
Q6
Ord1(6) pic.twitter.com/x0kUPgYtjq
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
製品idをカスタム分割します。"-"で最初の1列を取り出します。名前の編集から、製品カテゴリに変更します。シートで製品カテゴリごとの売上を出します。
(おまけ)
データペインからも分割することができます。
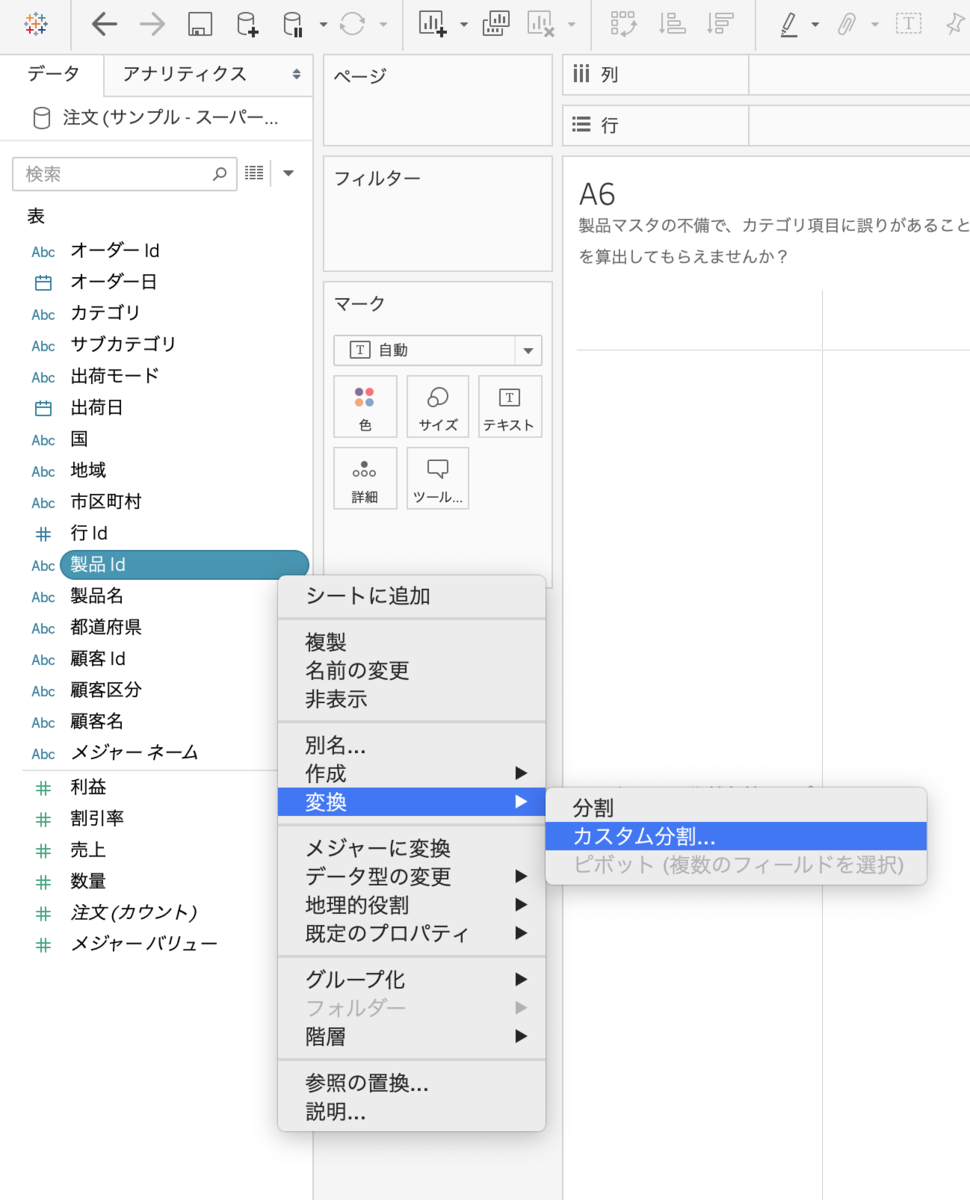
Q7
Ord1(7) pic.twitter.com/4rfpXGvSyB
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
サブカテゴリごとに数量、売上、利益を出します。利益を売上の軸にドラッグ&ドロップして、複合グラフにします。メジャーバリューと数量を二重軸にします。メジャーネームをとって、数量を棒グラフに、メジャーネームを線に変更します。数量の降順にします。
Q8
Ord1(8) pic.twitter.com/a5twLlAZC3
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
地域、顧客区分ごとの売上を出します。手動で地域を北から順に並べます。テキストを表示させます。売上の書式設定から、数値(カスタム)で百万(M)単位にして、小数点を0にします。今回は地域ごとの比較ができればいいので、軸の編集から独立した軸範囲にします。
Q9
Ord1(9) pic.twitter.com/Oifa5ZdtYM
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
オーダー日(年月)ごとの数量を出します。カテゴリを色に入れて、数量を簡易表計算から累計にします。事務用品を除外します。明確に開いた年月を知るために、数量を複製して、簡易表計算を編集します。先ほど出した累計の差を知りたいので、セカンダリ計算を追加して(チェックして)、差を選択します。今のままだと累計のオーダー日の前の値との差を出していますが、家具と家電の差を知りたいので特定のディメンションから、カテゴリを選択します。基準は前の値(家具)なので、数量累計の、家具から見た家電との差のグラフを出すことができます。 インジケーターは非表示にします。このNULL48個は家具のものです。(家具には前の値がないので差をだせない)
このグラフを棒グラフにして、数量累計の差を色に入れます。そのまま色に入れるとカテゴリを入れると下のように壊れてしまいます。
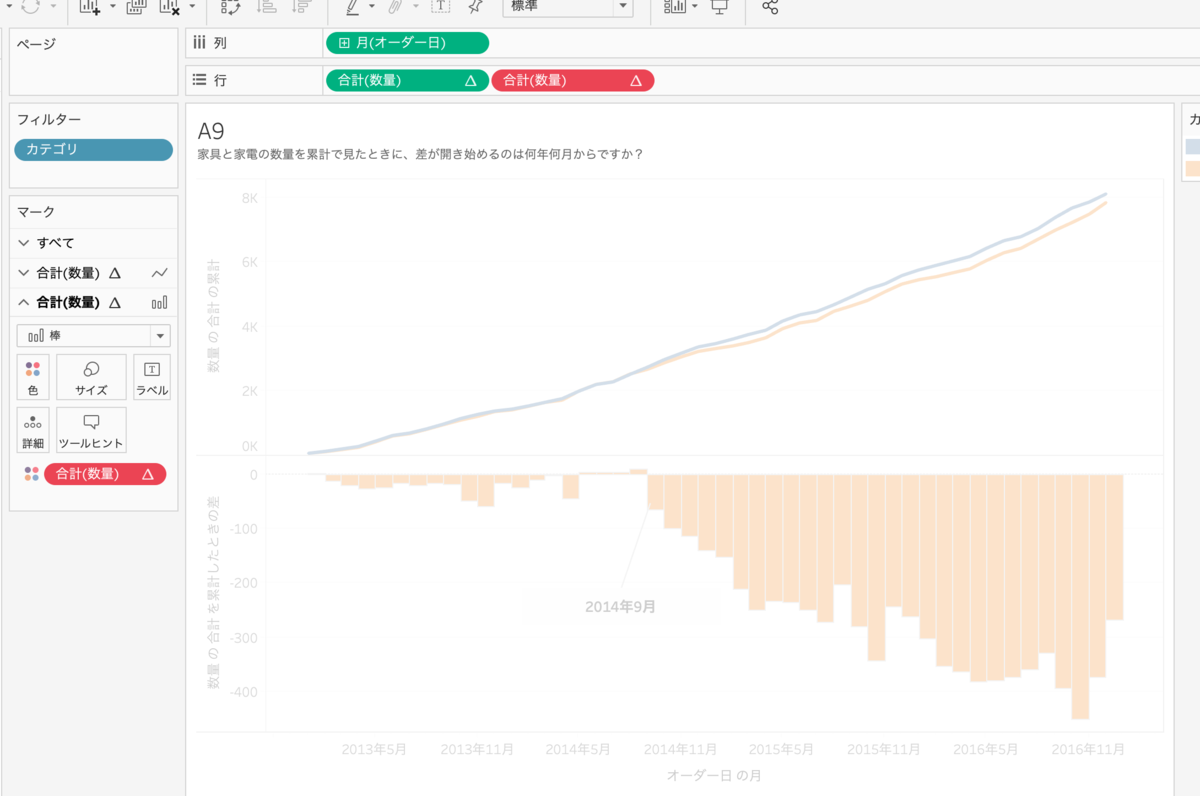
それは簡易表計算にカテゴリを使っているため、カテゴリを消してしまうと表計算ができなくなってしまうのです。そのため、一度カテゴリを詳細に変えてから、数量累計の差を色に入れます。強調するために、差が開いたオーダー年月を注釈にします。
Q10
Ord1(10) pic.twitter.com/pTJH04gfZC
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
顧客名のカウント(個別)(顧客数)を列に、売上を行に入れます。
散布図を作る際は、原因が横軸、結果が縦軸です!
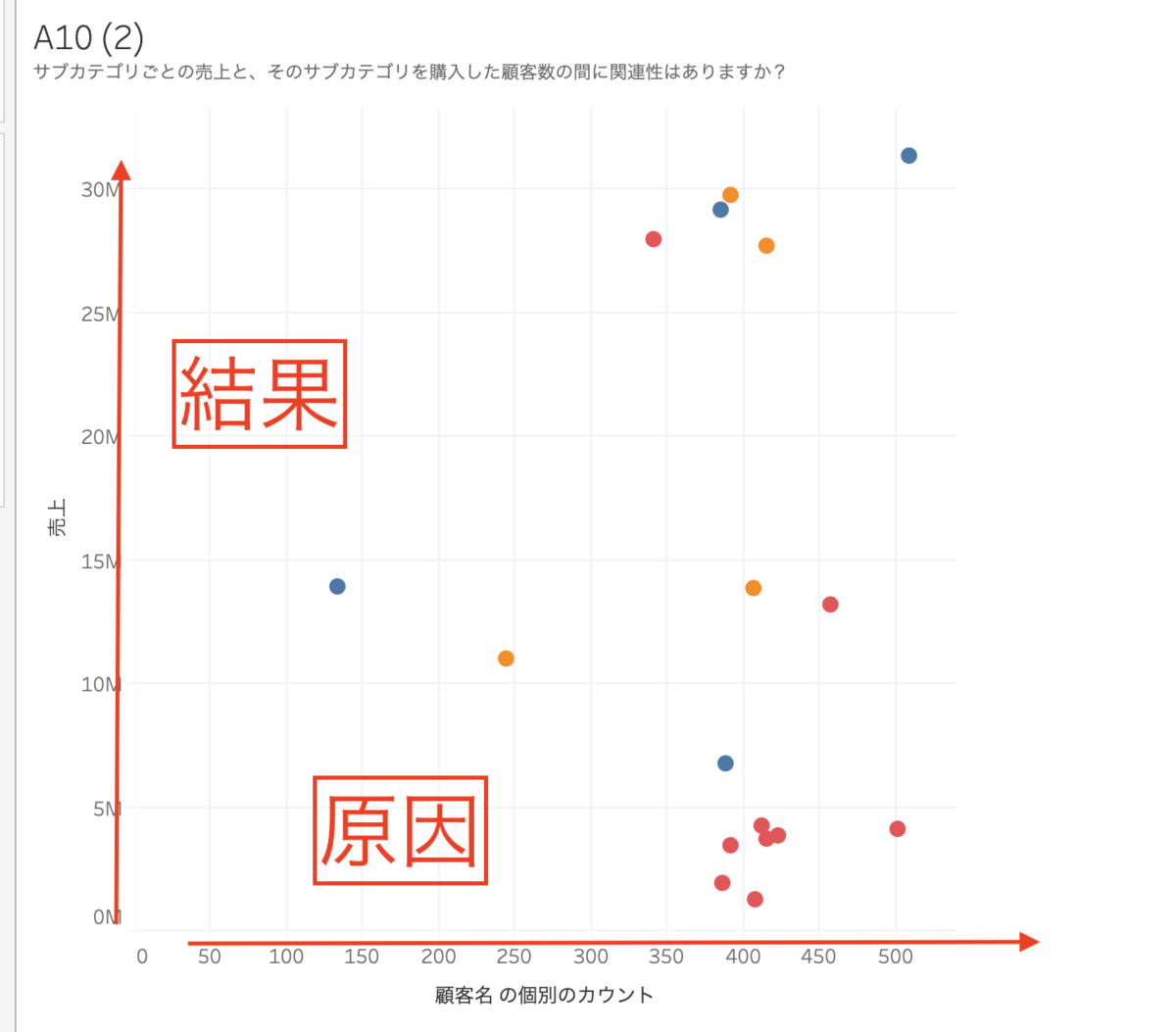
サブカテゴリを詳細に入れます。するとサブカテゴリが、ビューに出てきます。見づらいの円に変えます。それからアナリティクスペインから傾向線を入れます。すると関連性はないようです。
(おまけ)本当に関連性ない?
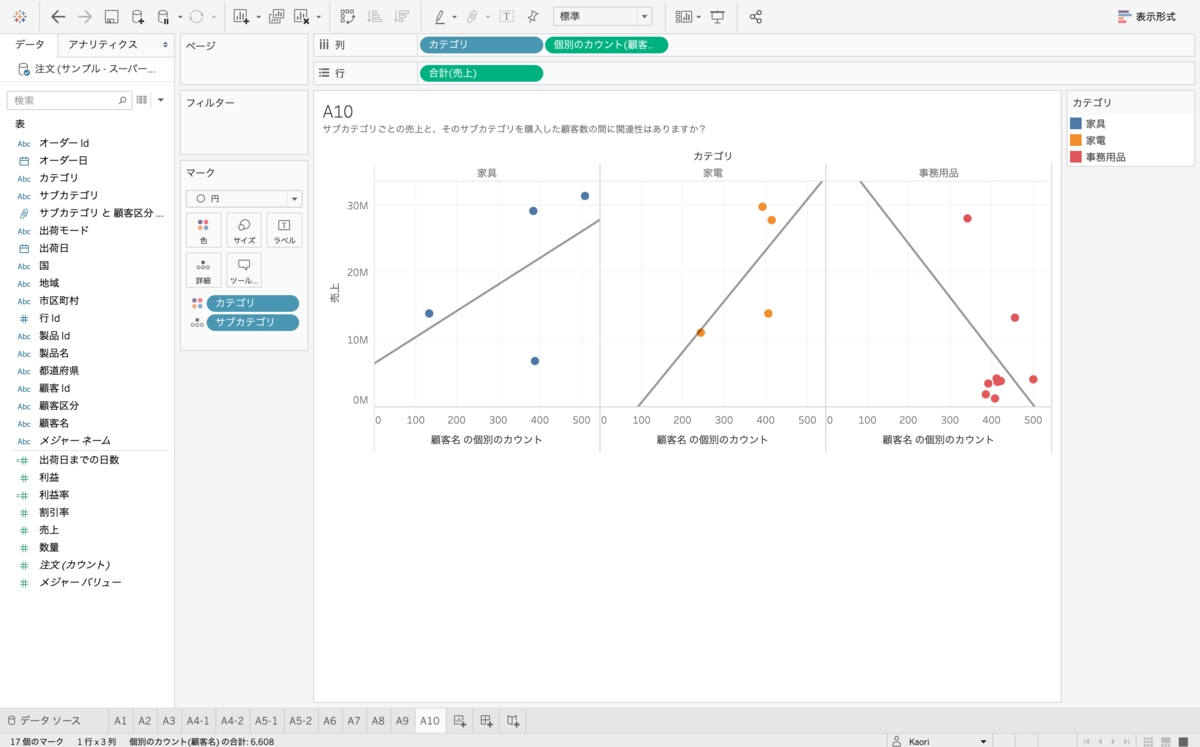
先ほどの散布図では顧客数と売上に関連性がないように見えましたが、カテゴリで分けるとどうでしょうか。カテゴリごとであればありそうです。色々な視点で深掘りしていくのは大切ですね・・・
Q11
Ord1(11) pic.twitter.com/HPxG1ySORt
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
オーダー日(曜日)ごとの顧客数(顧客名(個別のカウント))を出します。テキストで最大値のみ表示させます。
Q12
Ord1(12) pic.twitter.com/zD6CXJiFo4
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
オーダー日(年・曜日)ごとに利益率を出します。
kaodora.hatenablog.com
まず売上と利益をビューに入れてから、計算フィールドを開いてドラッグ&ドロップします。データペインから作成した利益率を選択して、デフォルトのプロパティから数値形式をパーセンテージにします。利益率を列に入れます。チャートを棒グラフにして、利益率の軸からリファレンスラインを追加します。表に定数0.15(15%)を設定します。マークのシェルフで、利益率>0.15を作成し色に入れて、利益率が15%を超えたものに色を入れます。
(おまけ)
アナリティクスペインの定数線からも入れることができます。
Q13
Ord1(13) pic.twitter.com/N3ku9ls2sy
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
サブカテゴリと顧客区分の組み合わせで割引率を出します。
"相対的"というのは2分できればいいので、割引率を色にしてステップドカラーを2ステップにします。すると、テーブルの全区分と画材の小規模事務所が相対的に割引率が高いことがわかります。この4つを1つのグループにします(*)。このグループを割引率が高い、という名前に変えて売上と利益率を比較します。利益率の方を棒グラフに帰ると、どうやら割引率が高いグループは利益率が低いようです。
*グループ化するとき、さらっと「すべてのディメンション」を選択したのですが、他の項目を選択するとどうでしょうか。
○「サブカテゴリ」にした場合

選択したもののサブカテゴリ全てがグループになってしまいます。
○「顧客区分」

選択したものの顧客区分全てがグループになってしまいます。
今回はテーブルの全区分と画材の小規模事務所のみをグループ化したいため、「すべてのディメンション」を選択する必要があるのです。逆にたくさんの項目があるときは上記のやり方で効率化できそうですね。
Q14
Ord1(14) pic.twitter.com/j6f6WEfRaC
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
オーダー日(年月)ごとに売上を出します。アナリティクスペインから、平均線を入れます。2013年の1番売上が低い月と、2015年の売上が高い月を選択(commandキーを押しながら両方選択)すると、この2つの平均線が出ます。全体の平均より高いことがわかります。
Q15
Ord1(15) pic.twitter.com/p1tkuTP54y
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
まず、シートで各年、月、カテゴリ、サブカテゴリ、顧客区分ごとの売上を示したクロス集計表を作ります。ダッシュボードでQ14のシートと組み合わせて、Q14シートの![]() をクリックする(フィルターとして使用)。それから折れ線グラフの数値の一つを押すと、下のクロス集計に年・月でフィルターされていることがわかります。
をクリックする(フィルターとして使用)。それから折れ線グラフの数値の一つを押すと、下のクロス集計に年・月でフィルターされていることがわかります。
ダッシュボードのアクションから、名前を変更し、アクションの実行対象を選択にします。それから、アクションの画面でフィルターを作成します。こちらは年のみでフィルターしたいので、ダーゲットフィルターでオーダー年を選択します。あとは同じように名前を変更して、実行対象をメニューに変更します。
棒グラフの数値を選択すると、フィルターが2つ現れ、年・月、年それぞれでフィルターすることができます。
Q16
Ord1(16) pic.twitter.com/yF18pMWqhv
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
まず出荷までにかかる日数を調べるために、計算フィールドを開きます。
DATEDIFF関数は指定された単位の2つの日付の差分を返すことができます。
DATEDIFF('day',[オーダー日],[出荷日])
オーダー日から出荷日までの差を日単位(day)で出してね、という式になります。
また、"面する"という問題文の表現には地図上で見る方が良さそうです。しかし、地域に地理的役割から国/地域を選択しても下のように地図上には現れません。

それはTableau上の国/地域とは日本のものではないからです。しかし、このデータでは地域は都道府県に割り当てられているため、都道府県から作成することで地域にも地理的役割を与えることができます。(動画参照)
地域を地図に出したら、出荷までにかかる日数を色で入れます。この時、メジャーを平均にすることを忘れないでください!それから行にカテゴリを入れて、カテゴリごとに出します。
出荷までにかかる平均日数が1番長い東北地方に面している地方の中で1番平均日数は中部地方です。その中部地方の事務用品での平均日数を注釈をつけて表します。
Q17
Ord1(17) pic.twitter.com/jmUbcXAEVQ
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
まず、売上と利益で散布図を作ります。製品名を詳細に入れて、チャートを円にします。それからアナリティクスペインでクラスターを売上の条件で設定します。
すると5つのクラスターに分かれました。クラスターはデータペインにドラッグ&ドロップすると、データとして扱うことができます。
別のシートでクラスターごとの顧客数(顧客名(個別のカウント))を出して、さらにカテゴリで分けます。クラスターに色をつけるとわかりやすいです!テキストで数字を入れると、事務用品の数が少ないことがわかりました。
ダッシュボードで散布図と棒グラフを組み合わせて、ダッシュボードのアクションからハイライトを設定するとそれぞれがどこに散布しているのかがわかりやすくなります!
(別解)
Ord1(17)-2 pic.twitter.com/XGqVllHGG3
— 動画掲載用 (@Fw1hBGrUf0CUZ3w) 2020年12月18日
上と同じように散布図を作り、売上のクラスターを入れます。
カテゴリを詳細に入れてハイライトを表示させると、カテゴリひとつひとつの散布が見れるようになります。今回は数が少ないので、このやり方でいいかもしれません!